Google Books APIで河童本の情報を収集できた!
今回、この結果を分析してみよう。
記事①:Pythonで検索してみよう ~Google Books APIを使ってみる ep1~
記事②:PythonでPython最新本を探す ~Google Books APIを使ってみよう ep2~
記事③:全検索結果を収集する ~Google Books APIを使ってみよう ep3~
前回、タイトルに「河童」を含む本をGoogle Books APIで全数収集しました。
データはCSVファイルに出力しています。
今回は、このデータを使って分析していきたいと思います。
ちなみに、今回はGoogle Books API自体は使いません!タイトルに偽りありです。
あくまでもGoogle Books APIを使って収集したデータを使うだけです。
(前回も書きましたが、お遊び程度のデータ分析という事で温かい目で見てくださいね。)
(2021年5月3日:学習開始73日目 PyQさんで勉強中!)
河童本のデータを収集していると、やはり妖怪界の神がごとき存在である、水木しげる先生の名前が何度か見られました。「河童の三平」がありますからね。
そういえば、昨年まで朝に「ゲゲゲの鬼太郎」をやっていました。
そこでENDINGテーマをうたっていたのが、「レキシ」です。
曲名が「GET A NOTE」。一見カッコいい名前ですが「下駄の音」からとってます。
ダジャレかい!って感じですが、曲はむしろ、GET A NOTEがぴったりくるクールな感じです。
アルバム「ムキシ」に収録されています。アルバムは多様な曲があって楽しいです。
「♪君に家督をゆずりた~い」とか「♪枕草子を片手に君はやってくるぅ」とか絶対楽しいでしょ?
(曲名から公式YouTubeに飛びます。)
さて、分析していきましょう。
1.今回やりたい事
冒頭に書いた通りですが、前回収集したデータを分析していきます。
前回のCSVデータを使いますが、プログラム上はほぼつながりがないので、あまり復習はしません。
データ収集の過程は、こちら。全検索結果を収集する ~Google Books APIを使ってみよう ep3~
さて、「どのようにデータ分析をしていくか?」です。
イメージとしては、
CSVデータをpandasライブラリで読み込む。
↓
データ分析しやすいように編集する。
↓
matplotlibライブラリでグラフにして分析する。
という感じです。
前回、データをpandasでまとめてcsvに出力しました。
今回、そのcsvをさらにpandasに戻すので、2度手間が強く見えます。
ただし、前回のプログラムからそのまま分析をすすめると、毎回APIにアクセスして、毎回データを取得してしまいます。
それを避けるために、まずはデータを確定させて、分析するような手法をとっています。
また、今回はAnacondaに付属している「Jipyter Notebook」を使っていきます。
Project Jupyter(wikipedia)
「Jipyter Notebook」の何が良いかっていうと、「対話型」の開発環境である点です。
「対話型」とは、書いたプログラムをその場で実行して、結果を見て次のプログラムを書いていくようなやり方です。
Pandasやmatplotlibでは、実行して出力されるデータをみると、予想外の結果になることがあります。
間違った動作という意味ではなく、正しく動作したうえで、想定外のグラフになったりする訳です。
結果を見たうえで、次のプログラムの内容が変わりうるような場合は、対話型の開発が適しているので、データ分析では「Jipyter Notebook」が良く用いられる。ということですね。
あと、「Jipyter Notebook」はPandasの表の表示が分かりやすいのも大きな利点です。
2.データを分析していこう① ~CSVファイル取り込み~
早速データを分析していきましょう。
最初にお断りしますが、「Jipyter Notebook」で記載するので、少し書き方が特殊です。
たとえば、あるデータフレーム「df」の中身を表示する場合、
通常でればprint(df)と記載します。
しかし、「Jipyter Notebook」では「df」だけで結果表示されます。
さて、やっていきましょう。
まずは「必要なライブラリのインポート」と「CSVファイルからデータのインプット」です。
インポートですが、ここも少し特殊な書き方(%matplotlib inline)をしています。
これは、「Jipyter Notebook」でのグラフプロットに必要なようです。
%matplotlib inline
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv('C:\Users\XXXXXXX\analysis_kappa_test.csv')
dfSyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UXXXXXXXX escapeはい、いきなりエラーです。
調べてもどういうエラーかは良く分かりませんが、解決法は分かりました。
ファイル名のまえに「r」をつければ解決できます。
%matplotlib inline
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv(r'C:\Users\XXXXXXX\analysis_kappa_test.csv')
dfUnicodeDecodeError: 'utf-8' codec can't decode byte 0x83 in position 0: invalid start byteまたもエラーです。しかしこれは、文字コードのエラーのようです。
これはCSV作成のときに文字コードCP932を選択しましたね。ここでも同じようにすれば良さそうです。
%matplotlib inline
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv(r'C:\Users\XXXXXXX\analysis_kappa_test.csv', encoding = 'cp932')
dfこのように出力されました。
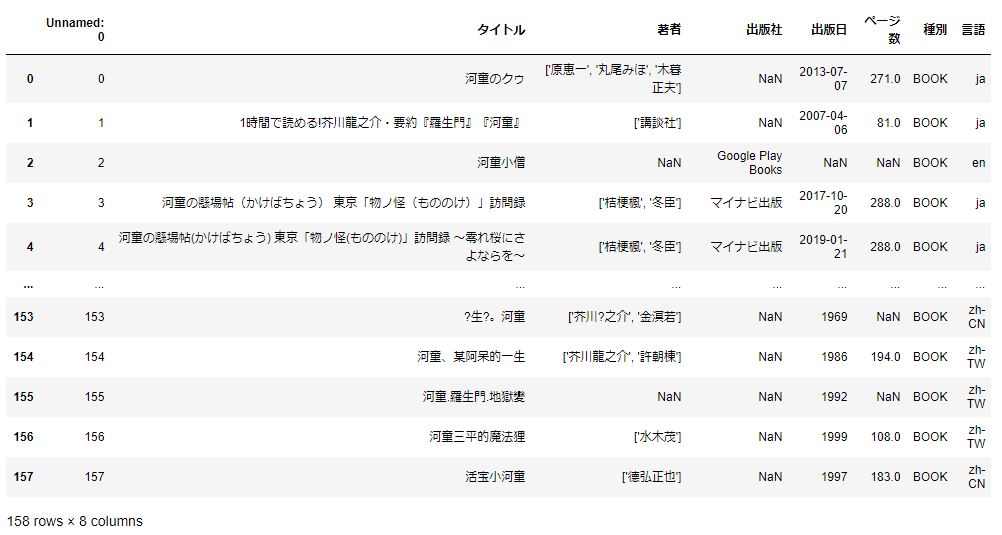
できました。見やすいですね。これが「Jipyter Notebook」の力だ!!
さて、次に行きましょう。
3.データを分析していこう② ~データの下準備~
取り込んだデータの処理を行っていきましょう。
下準備①:いらない列を消す。
まず気になるのが、取り込んだデータの左の行、列名が「Unnamed: 0」となっている列です。
これは不要なので消したいと思います。
「drop」で削除できます。やっていみましょう。
df2 = df.drop(0, axis=1)
df2KeyError: '[0] not found in axis'エラーですね。名前が付けられていないのでこの書き方ではダメです。
列の番号で消しましょう。
df2 = df.drop(df.columns[[0]], axis=1) #0番目の列削除
df2結果は以下です。
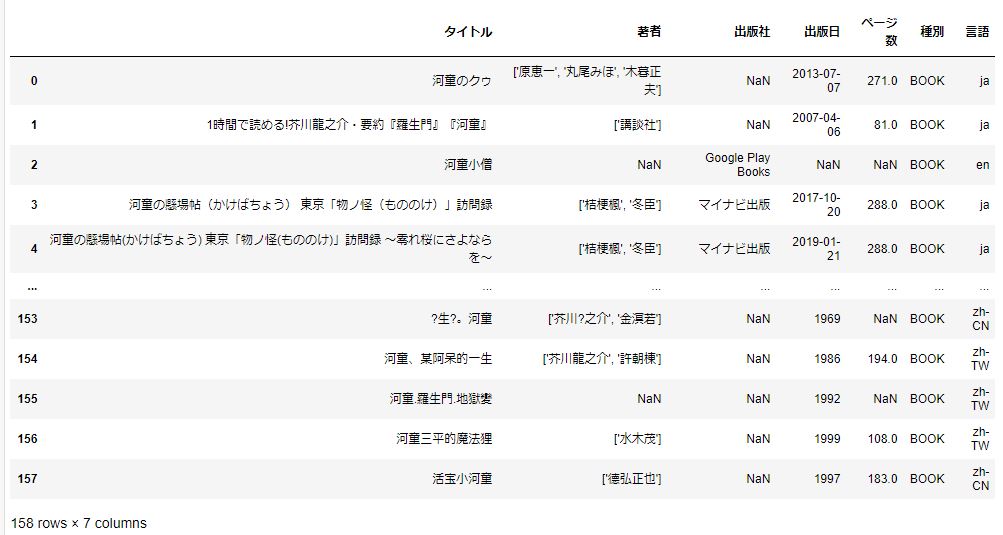
うまく削除できました。
下準備②:重複する行を確認する
次に、重複する行がないかを調べて、もしあれば削除します。
重複した行の抽出は「duplicated()」が使えます。
まずは「タイトル」が重なっている本を調べます。これは該当あると思います。
df2[df2.duplicated(subset='タイトル')] #タイトルが重複する本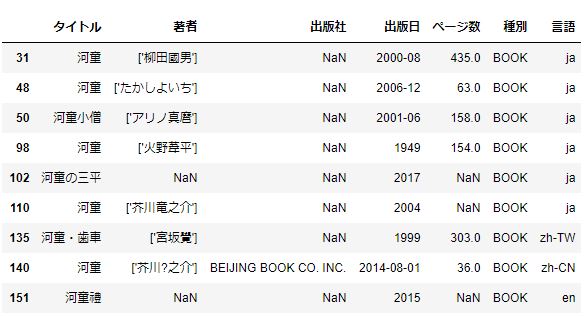
いくつか見つかりましたね。
つぎに、タイトル、著者、出版者が重なる本を探しましょう。
df2[df2.duplicated(subset=['タイトル', '著者', '出版日'])] #['タイトル', '著者', '出版日']が重複する本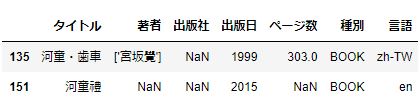
2件でました。これ、いずれも外国本なのが気になります。
重複項目に言語も加えましょう。
df2[df2.duplicated(subset=['タイトル', '著者', '出版日', '言語'])] #['タイトル', '著者', '出版日', '言語']が重複する本これ、出力結果はありませんでした。
どうやら、言語違いでの出版があったようです。
ということで、重複はないと思われます。
「重複はない」というのは一見良いことのように見えます。しかし実際は、この場合
「重複はない」=「取り損ねているデータがある」
だと思われます。
Google Books APIでデータを取得するときに、40件のデータ検索、40件ごとのStart Indexで回しましたが、Start Indexは30件ごとくらいにして、あえてカブるようにして取得して、その後データの重複を落とした方が良いのかもしれません。(今回はやりませんが・・・)
下準備③:データ形式を改変、統一する
分析をするにあたり、データの形式を整えていきましょう。
(実際には、グラフ描写をやってうまく行かなかったので形式を整えました。ややこしいので先に整えておきます。)
修正が必要なのは、「出版日」です。
まず見て分かるのが、情報が統一されていないという事です。
「年-月-日」「年-月」「年のみ」「なし」が見られます。
日時についてうまく処理するためのpandasモジュールとして、「to_datetime」があります。
これを使ってみましょう。
pd3 = pd.to_datetime(df2['出版日']) #datetime型に変換ParserError: Unknown string format: 19??本来ならばこれでOKですが、今回はなんと「19??」という「文字列」があり、変換できないようです。
これは厄介ですね。通常の方法では難しそうです。
作戦を変えます。改めてデータの形式を見てみると、形式は整っています。
つまり「年-月-日」になっていて、「年/月/日」のような形式はありません。
そこで、「-」でまず分割してみましょう。
まずは、「出版日」列のみのデータを取り出します。
pub_df = df2[['出版日']] #出版日列のみのデータ
pub_df.head() #冒頭5個のみ表示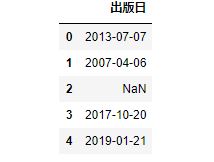
つぎに、「ー」で分割しましょう。文字列の分割は「str.split」が使えます。
pub_df = pub_df['出版日'].str.split('-', expand=True) # '-'で分割
pub_df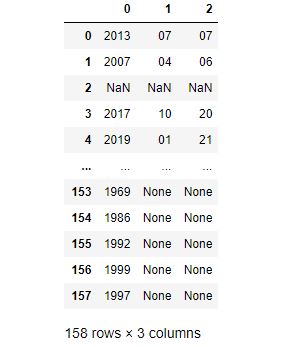
あえて、下の方までデータを出力しましたが、きちんと分かれています。
年のみのデータは、きちんと0列目に年が格納できてそうです。
次は、列名を直しましょう。
pub_df.columns=['Pub_year','Pub_month', 'Pub_day'] #列名変更
pub_df.head()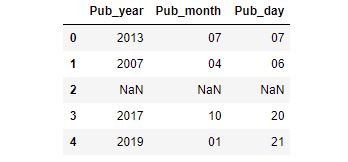
このデータのデータタイプを調べてみましょう。
データタイプは、「dtypes」で調べられます。
pub_df.dtypesPub_year object
Pub_month object
Pub_day object
dtype: objectデータタイプはいずれも「object」となっています。
これは、「文字列」または「文字列と数字が混在」を表しています。
いずれにしても、解析するには、「数字」にしておきたいと思います。
データタイプを変換するには、「astype」が使えます。
pub_df.astype(int) #整数に変換ValueError: cannot convert float NaN to integerエラーになりました。
欠損値NaNがfloat型でint型にできないっぽいことを言われています。
なら、float(小数型)にはできるのでしょうか?
pub_df.astype(float) #小数型に変換ValueError: could not convert string to float: '19??'エラーになりましたが、理由がことなります。
「19??」が文字列でfloatに変えられないようです。
「19??」問題はいったん置いて、先に「月 Pub_month」と「日 Pub_day」を変化しましょう。
pub_df['Pub_month'] = pub_df['Pub_month'].astype(float) #小数型に変換
pub_df['Pub_day'] = pub_df['Pub_day'].astype(float)
pub_df.head()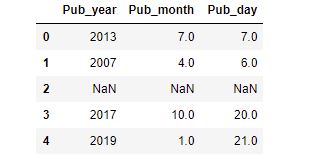
エラーが出ずうまく変換されたようです。小数になってますね。
「19??」問題を解決しましょう。
その前に、「19??」の行を抽出してみましょう。
抽出するには「query」が便利です。
pub_df.query("Pub_year == '19??'") #19??の抽出
0から数えて116行目にありました。
本題のデータ変換ですが、いろいろと調べると、「to_numeric」が使えるようです。
こちらを参考にさせていただきました。Pandasで欠損のある列の文字列型の数値を数値型に変換する
「to_numeric」はデータの形式を変換しつつ、変換できない場合、NaNにすることが可能です。
やってみましょう。
pub_df['Pub_year'] = pd.to_numeric(pub_df['Pub_year'], errors="coerce")
pub_df.head()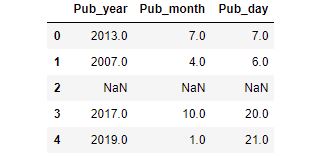
うまく出来ています。
では、改めてデータタイプを調べましょう。
pub_df.dtypesPub_year float64
Pub_month float64
Pub_day float64
dtype: object全て「float」に変換できていますね。
では、データフレームを結合しましょう。
index番号が元のデータフレームと同じなので、「join」が良いです。
(結合には、他にも「merge」や「concat」が使えますが使いどころが違います。)
df_conv = df2.join(pub_df) #df結合
df_conv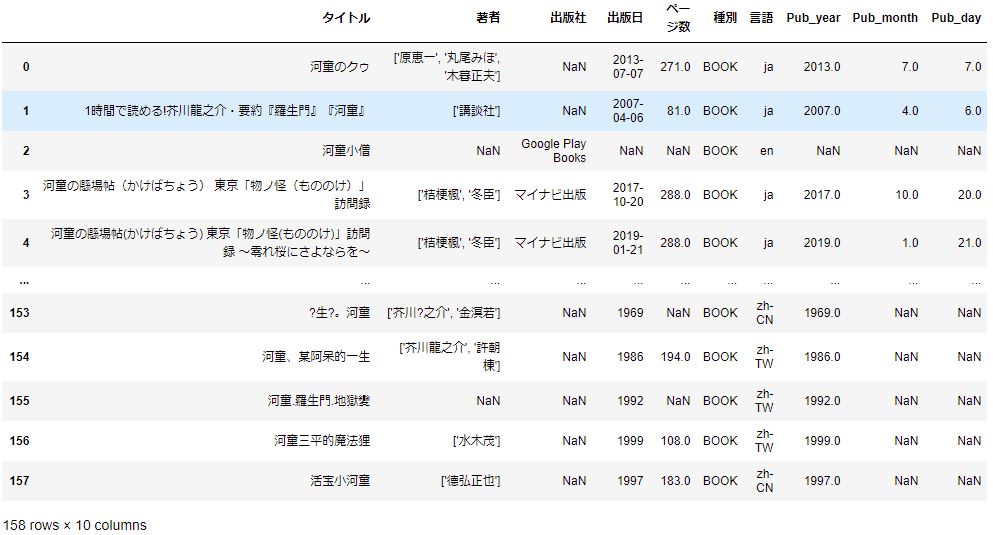
うまく結合できました。
ところで、例の「19??」行はどうなっているのでしょうか?
特定indexの行を抜き出すには、「iloc」が使えます。
行のIndexは116でした。
df_conv.iloc[116] #index116行を抽出タイトル 河童先生とその弟子
著者 ['中野実']
出版社 NaN
出版日 19??
ページ数 127
種別 BOOK
言語 zh-CN
Pub_year NaN
Pub_month NaN
Pub_day NaN
Name: 116, dtype: object元データの出版日は「19??」のままですが、変換した「Pub_year」はNaNになっています。
ちなみに、これ、中国語の書籍だったようですね。
これでデータの下準備、前処理は完了です。
4.データを分析していこう③ ~データ分析~
いよいよ本編です。
しかし、前処理さえ終わってしまえば、あとはデータを見ていくだけです。
まず、軽く調べてみましょう。言語の項目の分析です。
df_conv['言語'].value_counts() #言語のカウントja 126
zh-TW 16
zh-CN 12
en 3
it 1
Name: 言語, dtype: int64それぞれ、言語コードで表現されています。
ja = 日本語
zh-TW=中国語(繁体字)
zh-CN = 中国語(簡体字)
en = 英語
it =イタリア語
です。
では、このイタリア語の本を抽出してみましょう。
df_conv[df_conv['言語']=='it'] #イタリア語の抽出
Ryunosuke Akutagawa、芥川龍之介の河童ですね。
イタリア語訳が2008年に出ているようです。さすがに文豪は強い!
では、これをグラフにしてみましょう。
plt.hist(df_conv['言語'])
plt.show()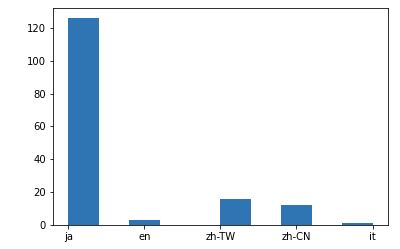
体裁は整えていませんが、グラフにはなりました。
当然、日本語が大多数ですね。
つづいて、「種別」も見てみましょう。
df_conv['種別'].value_counts()BOOK 158
Name: 種別, dtype: int64全て、「BOOK」本です。
まあ、河童をタイトルに入れる雑誌とかなさそうなので、妥当でしょう。
では、本題です。
まずは、データの全体像を見てみましょう。
全体像をみるには、「describe」が使えます。
df_conv.describe()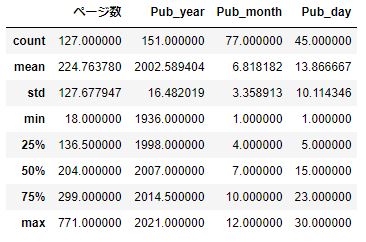
数値データの全体像が分かります。
データカウント数がまちまちなのは、データの欠損があるからですね。
ページ数は最大771ページ!なかなか凄いですね。
平均は224ページ、まあこんなもんでしょうね。
出版年は1936年~2021年の85年に渡っています。GoogleBooksのある本なので、それ以上古い古書はないという事でしょう。
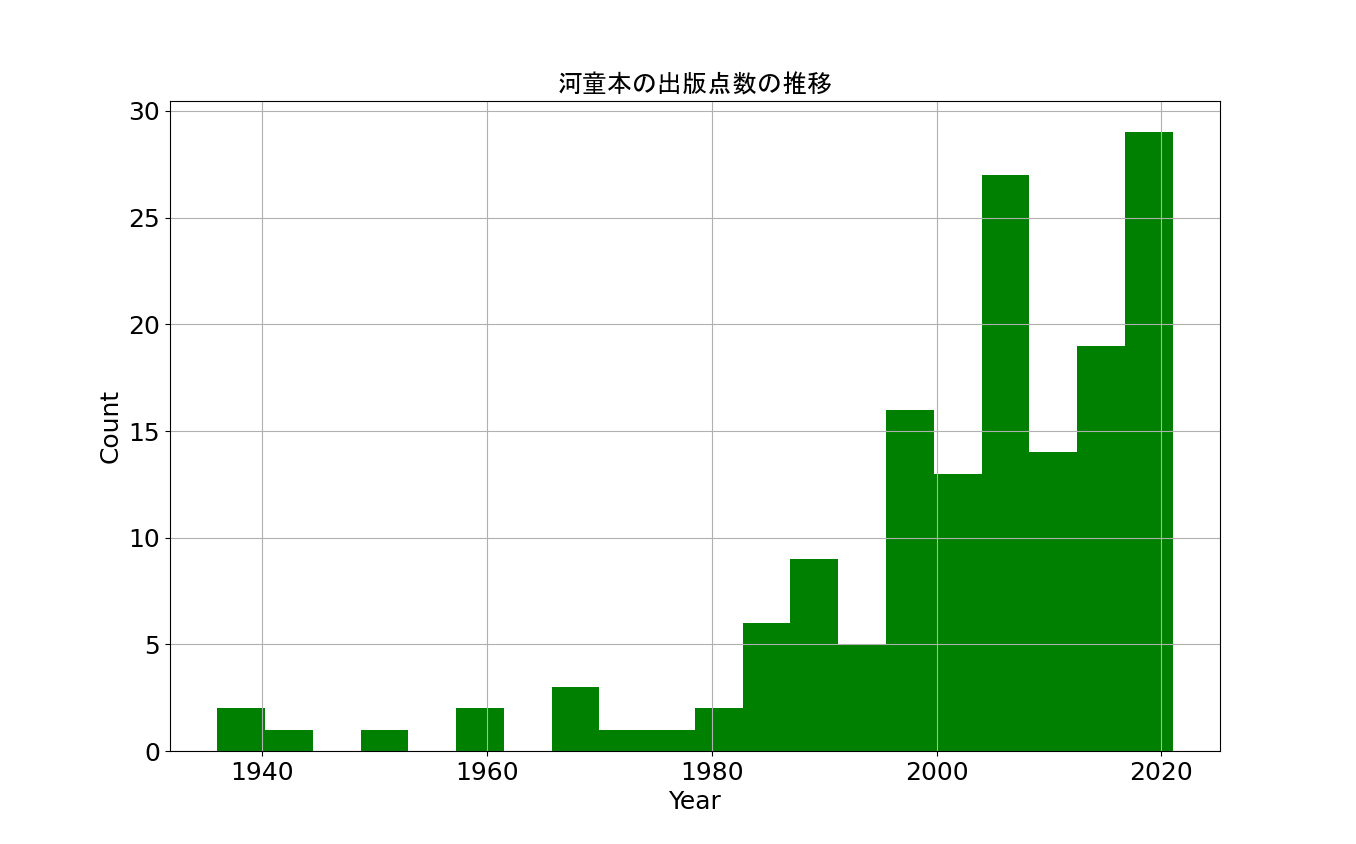
次は、出版年ごとのヒストグラムを作成しましょう。
plt.hist(df_conv['Pub_year'])
plt.show()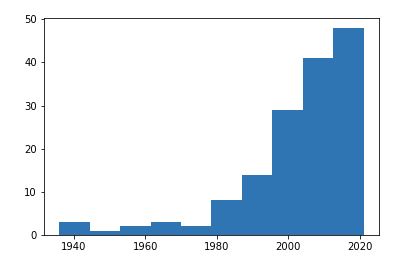
ヒストグラムの幅が大きすぎて、見えずらいですが増加傾向が見えます。
いくつか修正しましょう。
①:ヒストグラムの幅
②:横軸、縦軸の修正
③:グリットの追加
です。
fig = plt.figure()
plt.hist(df_conv['Pub_year'], bins=20, color= 'g') #20分割、緑色
plt.xlabel('Year') #x軸ラベル
plt.ylabel('Count') #y軸ラベル
plt.title('河童本の出版点数の推移', fontname="MS Gothic") #タイトル
plt.grid() #グリッド
plt.show()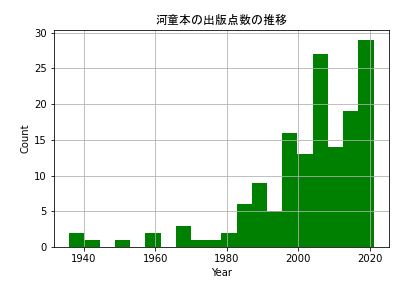
年ごとのグラフも書いてみましょう。
fig = plt.figure()
plt.hist(df_conv['Pub_year'], bins=85, color= 'c') #85分割 = 1年ごと、シアン色
plt.xlabel('Year')
plt.ylabel('Count')
plt.grid()
plt.show()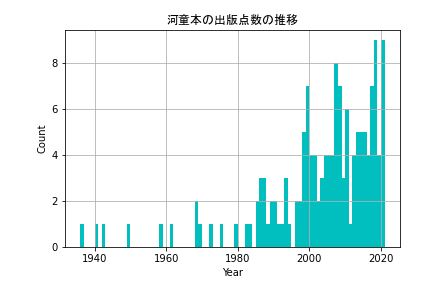
これらのグラフを見ると、年ごとに増えていることが分かります。
これは、大きく2つの理由が考えられます。
1つ目は、Google Booksの登録が新しいものほど多い。
2つ目は、出版点数の増加です。
1つ目はそのままです。Googleの設立がそもそも1998年です。
少なくともそれ以前のデータは、リアルタイムで収集出来ていないはずなので、データ点数が少なくなっている可能性があります。
2つ目が書籍全体の出版点数が増加しているという事実です。
こちらのページ(戦後の雑誌と書籍の発行点数をグラフ化してみる)にデータが分析されていました。
データによると、1960年から2019年までで書籍の出版点数は6~7倍程度に増えています。
冊数をしめす発行部数ではなく、種類を示す出版点数なので、今回のデータと比較するのに適しています。
この2つの観点から、今回のグラフの増加を説明できそうです。
このグラフはもう一つ特徴があります。
2008年くらいにピークがあります。
一方で、出版点数のグラフでは2013年にピークを迎えているのでズレがあります。
何があったのでしょうか?
2007年~2009年に出版された本を抽出してみましょう。
df_year_07_09 = df_conv.query('2007 <= Pub_year <= 2009') #2007~2009年出版の本
df_year_07_09.sort_values('Pub_year') #年でソート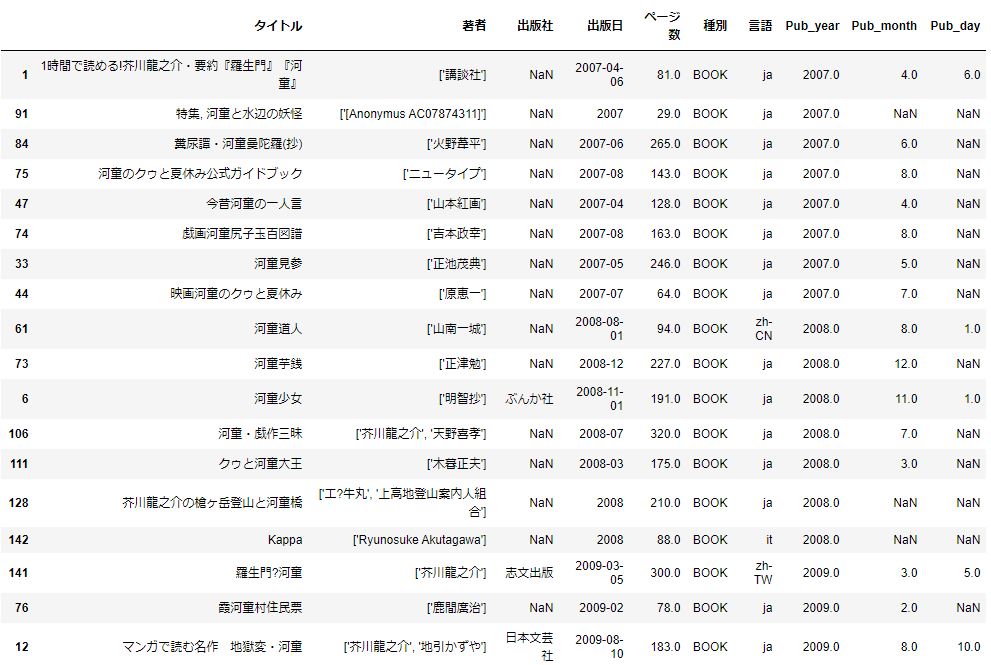
特徴的なのが、「河童のクゥ」というワードが見られます。
調べてみると、「河童のクゥと夏休み」という映画が2007年7月に公開されています。
そういえばおぼろげながら、あった気がします。
この「河童のクゥ」関連本や、これに乗っかって?芥川龍之介の「河童」がいろんな形態(マンガや1時間で読める)で何度か登場しています。
隠れた「平成河童ブーム」が2007年~2008年周辺にあったという事をみつけだしました。
次は、月ごとの出版点数を見てみましょう。
fig = plt.figure()
plt.hist(df_conv['Pub_month'], bins=12, color= 'y') #12分割 = 1月ごと、シアン色
plt.xlabel('Month')
plt.ylabel('Count')
plt.title('月ごとの河童本の出版点数', fontname="MS Gothic") #タイトル
plt.grid()
plt.show()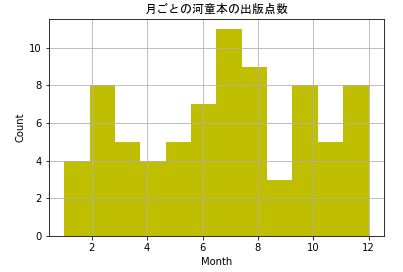
7月、8月が2トップですね。やっぱり、「妖怪は夏」なんですね。
次は、出版年とページ数の相関を見てみましょう。
df_conv.plot.scatter(x='Pub_year', y='ページ数')
plt.ylabel('ページ数', fontname="MS Gothic")
plt.title('河童本の出版年とページ数の関係', fontname="MS Gothic") #タイトル
plt.grid()
plt.show()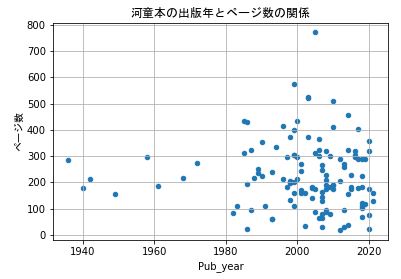
1980年以降、ページ数の少ない本が増加しています。
これは、Googleのデータ収集問題もありますが、ページ数の少ない本の増加が出版点数の増加にも繋がっているのかもしれません。
気になるのは、突出してページ数の多いページページ越えの本です。
これを抽出してみましょう。
「idxmax」を使うと最大値をもつIndexを取得できます。
さらに、「iloc」を使うとそのindexをもつ列を取得できます。
df_conv.iloc[[df['ページ数'].idxmax()]] #ページ最大の列を抽出
「河童伝承大事典」!!!凄い本もあるんですね。
調べると、辞書のような本です。APIではNaNですが、著者は和田 寛さんという方だそうです。
入手は困難なようです。
いろいろと分析してきました。
最大の収穫は、隠された「平成河童ブーム」を発見できたところですかね。
「令和河童ブーム」が来ることを期待しましょう。
これにて、終了です!!
FIN.
PyQさんで勉強中!


コメント