
Google Books APIで検索が出来るようになってきた。
出てきたデータを使って研究してみよう
記事①:Pythonで検索してみよう ~Google Books APIを使ってみる ep1~
記事②:PythonでPython最新本を探す ~Google Books APIを使ってみよう ep2~
過去2回でGoogle Books APIを使って、検索をやってきました。
前回、PythonでPython最新本の検索をすることができました。
APIって便利ですね!
使いこなせばWEBの新たな世界が広がる感じがしました。
では、今回はGoogle Books APIを使って簡易的に研究をしてみようと思います!
取り上げるテーマは私、「河童」
(ただし、まあお遊び程度と考えてくださいね。)
(2021年5月2日:学習開始72日目 PyQさんで勉強中!)
今回は河童関連の曲を聴いていきたいと思います。
妖怪ヘヴィメタルバンド「陰陽座」のアルバム「夢幻泡影」から「河童をどり」・・・と行きたいのですが、公式音源がない!ので同じアルバムからの曲「「夢幻」〜「邪魅の抱擁」」(Live DVD『式神雷舞』Official Preview)」を紹介します。
この曲はカッコ良い!そして「河童をどり」はがっつり河童について歌っていてコミカルな曲です。
おそらく、河童の生態をうたった世界唯一の曲だと思います。
それともう1曲、こっちは悪魔メタルバンド「聖飢魔Ⅱ」の「Joker ~非力河童人間~」を、といきたかったのですが、こちらは公式音源ないです。
ということで、こっちもカッコ良い曲「GO AHEAD! (地獄の再審請求 -LIVE BLACK MASS 武道館- )」です。
「非力河童人間」読めます?正解は「ひりきかっぱマン」。
この「非力」と「河童」と「マン」をつなげるセンスよ!
で、曲の方は調子に乗ってる人間どもを「非力河童人間」と揶揄してる感じです。
いや、あくまでも「悪魔的に言うと」ですよ。
(両曲とも、曲名から公式YouTubeに飛びます。河童曲をやってる2バンドともやたら演奏力が高いのはなぜでしょう?)
私は両曲とも手元にあるので、聴きながらやっていきます!
では、行きましょう!
(今回は、Google Books APIの検索結果を全件収集するところまで進みます。最後にプログラムがあります。)
1.前回の振り返り
前回の最後に「Pythonの最新本を調べる」という事をやりましたが、実際に作ったプログラムはインプットする項目を変えれば、検索条件を変えれるような内容になっています。
まず、前回のプログラムでtitle=河童で検索してみましょう。
前回のプログラムから、検索項目と出力先を変えた
import requests
import json
import pandas as pd
import csv
""" input field """
""" 検索ワード入力 """
search = {
'free' : '', #free word
'title' : '河童',
'publisher' : '',
'subject' : '',
'isbn' : '',
'lccn' : '', #Library of Congress Control Number
'oclc' : '', #Online Computer Library Center number
}
""" 検索件数入力"""
""" 検索件数入力"""
resurlt_num = 20 #検索件数、未入力なら10
""" 言語入力"""
lnaguage = 'ja' #日本語なら'ja'入力
""" ソート入力"""
sort = 'newest' #新しい順なら'newest'を入力。デフォルト(未入力)はrelevance
""" 出力csvファイル名入力"""
output_filename = 'kappa.csv' #.csv形式で名前を入力
""" input field 終了"""
def url_q():
title_q = '' if search['title']=='' else 'intitle:'+search['title']
publisher_q = '' if search['publisher']== '' else 'inpublisher:'+search['publisher']
subject_q = '' if search['subject']== '' else 'subject:'+search['subject']
isbn_q = '' if search['isbn']== '' else 'isbn:'+search['isbn']
lccn_q = '' if search['lccn']== '' else 'lccn:'+search['lccn']
oclc_q = '' if search['oclc']== '' else 'oclc:'+search['oclc']
q_list = [search['free'], title_q, publisher_q, subject_q, isbn_q, lccn_q, oclc_q]
q_list_2 = list(filter(None, q_list))
url_q = 'q=' + '+'.join(q_list_2)
return url_q
def url_generation():
base_url = 'https://www.googleapis.com/books/v1/volumes?'
url_max = 'maxResults='+ str(resurlt_num)
url_lnag = '' if lnaguage == '' else 'langRestrict='+lnaguage
url_sort = '' if sort == '' else 'orderBy='+sort
url_list = [url_q(), url_max, url_lnag, url_sort]
url_list_none = list(filter(None, url_list))
url = base_url + '&'.join(url_list_none)
return url
def main(url, num):
response = requests.get(url).json()
totalitems = response['totalItems'] #件数
print('件数:', totalitems)
book_df = pd.DataFrame(index=[], columns=['タイトル', '著者',
'出版社', '出版日', 'ページ数', '種別', '言語', '要約']) #Data Frame作成
items_list = response['items'] #items リストデータ
for i in range(num):
items = items_list[i] #items
info = items.get('volumeInfo')
title = info.get('title')
author = info.get('authors')
publisher = info.get('publisher')
publisheddate = info.get('publishedDate')
pages = info.get('pageCount')
printtype = info.get('printType')
description = info.get('description') #要約
language = info.get('language')
book_df= book_df.append({'タイトル': title,
'著者' : author,
'出版社' : publisher,
'出版日':publisheddate,
'ページ数':pages,
'種別':printtype,
'言語':language,
'要約':description}, ignore_index=True)
print(book_df)
book_df.to_csv(output_filename, encoding='CP932') #csvファイル出力
with open(output_filename, 'a', newline='') as f:
writer = csv.writer(f)
writer.writerow(['URL', url])
writer.writerow(['総件数', totalitems])
url = url_generation()
main(url, resurlt_num)
出力結果です。
件数: 173
タイトル 著者 出版社 出版日 ページ数 種別 言語
要約
0 河童のクゥ [原恵一, 丸尾みほ, 木暮正夫] None 2013-07-07 271 BOOK ja クゥとさよならしてから6年目、康一は進学
校の高二になっていた。みんなについていけず、ほんのり...
~~~~~略~~~~~
File "pandas\_libs\writers.pyx", line 69, in pandas._libs.writers.write_csv_rows
UnicodeEncodeError: 'cp932' codec can't encode character '\u2014' in position 104: illegal multibyte sequence
はい、いきなりエラーが出ました。
想定外ですが、これは修正しないといけなさそうです。
エラーの内容は、文字コード(\u2014)がCP932では読めないって出ています。
文字コード(\u2014)は「—」だそうです、、、
今回、古い本もDigるので対処が必要ですね。
ただ、一つ分かったのは、件数は173件です。
1回最大40件回収できるので、5回で回収できるはずですね。
これを回収したいと思います。
2.今回やりたい事と修正する点
まずは、今回やりたい事と修正したい点をまとめてみましょう。

修正点については、やっていく中でも出てくると思います。
まずは、この方針でやってみたいと思います。
3.作戦会議
まずは、Google Books APIs公式ページを見てみましょう。
ここを見ていくと、「Pagination」の項目に「startIndex」があります。
これは、「検索した結果のうち、どの位置からデータを集めるか?」を表す項目で、デフォルトは0です。
これをうまく使えば、全件回収できそうです。
ただし、あまりに検索件数が多いとサーバーに負荷をかけてしまうので、事前にチェックをかけれるようにしたいと思います。
また、今回は大丈夫そうですが、「回収件数はMAXで400件にしたい」と思います。
さらに、「複数回APIにアクセスすることになるので、アクセスする間隔をあけれるようにしたい」と思います。ここは非常に重要で、私が学習した書籍やサイト、すべてで言及されていました。
では、ここまでをフローチャートにしてみましょう。CSVファイル出力までです。
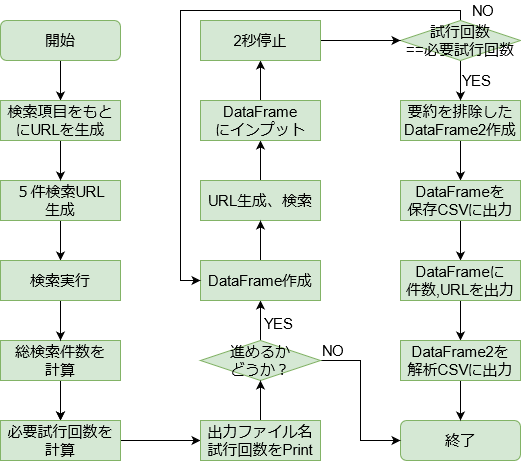
では、やっていきましょう。
4.プログラムを書いていこう① ~文字コードエラー修正~
進める前に、さっき出てきたエラーを解決しておきましょう。
UnicodeEncodeError: 'cp932' codec can't encode character '\u2014' in position 104: illegal multibyte sequenceこれは、データフレームをCSVファイルに置き換えるときに発生しています。
前回、encodingなしでやると盛大に文字化けしたので、encodingなしはNGです。
解決策①:encodingを変える
日本語コードとしては、今回使っている「CP932」以外に一般的なところで「Shift_Jis」がありますが、前回これはNGでした。
それ以外に、「euc_jp」や「 iso2022_jp」があります。
これでいければOKですが、実際にやってみましたがうまく行きませんでした。
他の文字で引っかかります。別の解決策を考えましょう。
解決策②:関数をよく調べる
基本に戻って、関数をよく調べてみましょう。
今回引っかかっているのは、「Pandasライブラリ」の「to_csv関数」です。
公式ドキュメントをよく読むと、to_csv関数の引数の中に「errors」という項目があり、さらに詳しく調べると、「errors=’ignore’」で無視、「errors=’replace’」でエラーを?に置き換えるようです。
これは使えそうです!!
ちなみに、open関数(with open()~~とかでファイルを開いたり書き込みしたりするやつです。)から書き方を引っ張て来ているので、こっちでも使えます。ためになったねぇ~~。
では、プログラムをこのようにして走らせてみます。
~~~~略~~~~~
print(book_df)
book_df.to_csv(output_filename, encoding='CP932', errors = 'replace') #csvファイル出力, エラー置き換え
~~~~略~~~~~
url = url_generation()
main(url, resurlt_num)
結果はココには記載しませんが、エラーは出ず、csvファイルもうまく書き込めていました。
まずは1個解決です。関数を調べるのはめちゃくちゃ大事ですね!
5.プログラムを書いていこう② ~5件検索から試行回数計算まで~
プログラムを書いていきましょう
今回、検索数については、自分で決める必要がありません。
件数については、自動で設定できるようにしようと思います。
まずは、検索数を5に設定して、総検索数を算出しましょう。
試行回数 = 1 + 総検索数/40 で計算できます。
このとき、検索の妥当性を判断するため、「タイトル」、「著者」を出力されるようにしましょう。
この辺りまでを関数にまとめましょう。前回のプログラムを応用しましょう。
import requests
import json
import pandas as pd
import csv
""" input field """
""" 検索ワード入力 """
search = {
'free' : '', #free word
'title' : '河童',
'publisher' : '',
'subject' : '',
'isbn' : '',
'lccn' : '', #Library of Congress Control Number
'oclc' : '', #Online Computer Library Center number
}
""" 検索件数入力"""
#resurlt_num = 20 #全件検索の場合は未設定
""" 言語入力"""
lnaguage = '' #日本語なら'ja'入力
""" ソート入力"""
sort = '' #新しい順なら'newest'を入力。デフォルト(未入力)はrelevance
""" 出力csvファイル名入力"""
output_filename = 'kappa_test.csv' #.csv形式で名前を入力
""" input field 終了"""
def url_q():
~~~~~略~~~~~
def url_generation():
base_url = 'https://www.googleapis.com/books/v1/volumes?'
#url_max = 'maxResults='+ str(resurlt_num) ここでは検索件数を設定しない
url_lnag = '' if lnaguage == '' else 'langRestrict='+lnaguage
url_sort = '' if sort == '' else 'orderBy='+sort
url_list = [url_q(), url_lnag, url_sort]
url_list_none = list(filter(None, url_list))
url = base_url + '&'.join(url_list_none)
return url
def first_search(url):
url_1st = url + '&maxResults=5'
response = requests.get(url_1st).json()
totalitems = response['totalItems'] #件数
book_df_1st = pd.DataFrame(index=[], columns=['タイトル', '著者'])
items_list = response['items']
for i in range(5):
items = items_list[i]
info = items.get('volumeInfo')
title = info.get('title')
author = info.get('authors')
book_df_1st = book_df_1st.append({'タイトル': title,
'著者' : author,}, ignore_index=True)
num_cycle = int(1 + (int(totalitems) / 40)) #試行回数 = 1 + 総件数/40
return totalitems, num_cycle, book_df_1st
url = url_generation()
totalitems, num_cycle, book_df_1st = first_search(url)
print(url)
print(f'総件数:{totalitems}、試行回数:{num_cycle}')
print(book_df_1st)
結果は以下です。
総件数:181、試行回数:5
タイトル 著者
0 河童のクゥ [原恵一, 丸尾みほ, 木暮正夫]
1 1時間で読める!芥川龍之介・要約『羅生門』『河童』 [講談社]
2 河童小僧 None
3 河童の懸場帖(かけばちょう) 東京「物ノ怪(もののけ)」訪問録 [桔梗楓, 冬臣]
4 河童の懸場帖(かけばちょう) 東京「物ノ怪(もののけ)」訪問録 ~零れ桜にさよならを~ [桔梗楓, 冬臣]次に進めるかどうかを確認する関数をつくりましょう。
まず、保存ファイルを表示して、進めるかどうかを確認したいです。
もしNGなら終了させますが、終了は「sys.exit()」で出来るようです。
ただし、sysモジュールのimportが必要です。
そのあと、算出した試行回数を表示して、試行回数を入力するようにします。
試行回数は最大10(10ループ、検索件数400件)までにします。
また、実際の試行回数は、算出した試行回数以下にする必要があります。
これらを踏まえてプログラムを書いていきます。
import requests
import json
import pandas as pd
import csv
import sys
""" input field """
~~~~~略~~~~~
def check(file_name, totalitems, num_cycle):
print('保存ファイル:'+file_name)
check_yn = input('ファイル名OK? OK → y, No → any key:')
if check_yn == 'y':
pass
else:
sys.exit()
print(f'総件数:{totalitems}、全取得に必要な試行回数:{num_cycle}')
print('実行する試行回数を9以下の数字で入れてください。1~10以外で終了します。')
while True:
inp_num_cycle = int(input('実行する試行回数:'))
if inp_num_cycle > num_cycle or inp_num_cycle > 10:
print('試行回数が多すぎます')
else:
return inp_num_cycle
break
~~~~~略~~~~~
url = url_generation()
totalitems, num_cycle, book_df_1st = first_search(url)
print(url)
print(book_df_1st)
inp_num_cycle = check(output_filename, totalitems, num_cycle,)
print(f'試行回数:{inp_num_cycle}')実行結果です。
タイトル 著者
0 河童のクゥ [原恵一, 丸尾みほ, 木暮正夫]
1 1時間で読める!芥川龍之介・要約『羅生門』『河童』 [講談社]
2 河童小僧 None
3 河童の懸場帖(かけばちょう) 東京「物ノ怪(もののけ)」訪問録 [桔梗楓, 冬臣]
4 河童の懸場帖(かけばちょう) 東京「物ノ怪(もののけ)」訪問録 ~零れ桜にさよならを~ [桔梗楓, 冬臣]
保存ファイル:kappa_test.csv
ファイル名OK? OK → y, No → any key:y
総件数:181、全取得に必要な試行回数:5
実行する試行回数を9以下の数字で入れてください。1~10以外で終了します。
実行する試行回数:90
試行回数が多すぎます
実行する試行回数:5
試行回数:5
うまく行きました。この場合、試行回数に「文字列」を入れるとエラーで止まります。
本来ならば修正した方が良いですが、まあ今回は良いでしょう。過去にやったし。
6.プログラムを書いていこう③ ~全検索結果を取得~
では、メインプログラムを書いていきましょう。
ここからは、前回のプログラムをかなり流用できそうです。
前回から変える点は、
①:試行回数分のループを行う。(for文で実行する試行回数分だけ回す)
②:ループの1回ごとに2秒間停止を行う。
③:保存用のCSVと解析用のCSVに分ける。
④:解析用CSVには、「要約」と検索URLを入れない。
こんなところです。
1つずつ見ていきましょう。
①:試行回数分のループを行う。(for文で実行する試行回数分だけ回す)
試行回数は、さきほど10以下で入力するようにしました。
たとえば、試行回数5なら5回ループを回せばよいです。
で、ループごとにURLを変える必要があります。
URLに付け加える内容は、「40件検索(固定)」と「取得開始インデックスをX」です。
「取得開始インデックスをX」ですが、
1回目ループ→0~39、X=0=40X0
2回目ループ→40~79、X=40=40X1
2回目ループ→80~79、X=80=40X2
となるので、X=40Xサイクル
とすれば良さそうです。
②:ループの1回ごとに2秒間停止を行う。
試行のループごとに一時停止を挟みます。
これは、timeモジュールをimportして、time.sleep(2)でできます。
ちなみに、だいたい「1秒以上間隔をあける」ことが推奨されているのでtime.sleep(1)でも良いですが、ちょっとビビッて2秒にしています。
まずは、ここまでをプログラムにしましょう。ちなみに今回から、検索条件から「言語=ja」を外しています。
import requests
import json
import pandas as pd
import csv
import sys
import time
~~~~~略~~~~~
def check(file_name, totalitems, num_cycle):
~~~~~略~~~~~
def main(url, cycle):
book_df = pd.DataFrame(index=[], columns=['タイトル', '著者',
'出版社', '出版日', 'ページ数', '種別', '言語', '要約'])
for c in range(cycle):
url_index = url+'&maxResults=40&startIndex='+str(c*40) #検索件数40, 開始index = 40*c
response = requests.get(url_index).json()
totalitems = response['totalItems'] #件数
items_list = response['items'] #items リストデータ
for i in range(40): #取得件数 = 40
items = items_list[i] #items
info = items.get('volumeInfo')
title = info.get('title')
author = info.get('authors')
publisher = info.get('publisher')
publisheddate = info.get('publishedDate')
pages = info.get('pageCount')
printtype = info.get('printType')
description = info.get('description') #要約
language = info.get('language')
book_df= book_df.append({'タイトル': title,
'著者' : author,
'出版社' : publisher,
'出版日':publisheddate,
'ページ数':pages,
'種別':printtype,
'言語':language,
'要約':description}, ignore_index=True)
time.sleep(2)
book_df.to_csv(output_filename, encoding='CP932', errors = 'replace') #csvファイル出力, エラー置き換え
with open(output_filename, 'a', newline='') as f:
writer = csv.writer(f)
writer.writerow(['URL', url])
writer.writerow(['総件数', totalitems])
url = url_generation()
totalitems, num_cycle, book_df_1st = first_search(url)
print(url)
print(book_df_1st)
inp_num_cycle = check(output_filename, totalitems, num_cycle,)
main(url, inp_num_cycle)一見大変そうですが、前回のプログラムからいじっているのは実質6行程度です。
では、実行してみましょう。
まずはサイクル=3にします。
タイトル 著者
0 河童のクゥ [原恵一, 丸尾みほ, 木暮正夫]
1 1時間で読める!芥川龍之介・要約『羅生門』『河童』 [講談社]
2 河童小僧 None
3 河童の懸場帖(かけばちょう) 東京「物ノ怪(もののけ)」訪問録 [桔梗楓, 冬臣]
4 河童の懸場帖(かけばちょう) 東京「物ノ怪(もののけ)」訪問録 ~零れ桜にさよならを~ [桔梗楓, 冬臣]
保存ファイル:kappa_test.csv
ファイル名OK? OK → y, No → any key:y
総件数:209、全取得に必要な試行回数:6
実行する試行回数を9以下の数字で入れてください。1~10以外で終了します。
実行する試行回数:3
試行回数:3ここで作ったプログラムは、CSVファイルに出力されているので、それを見てみましょう。
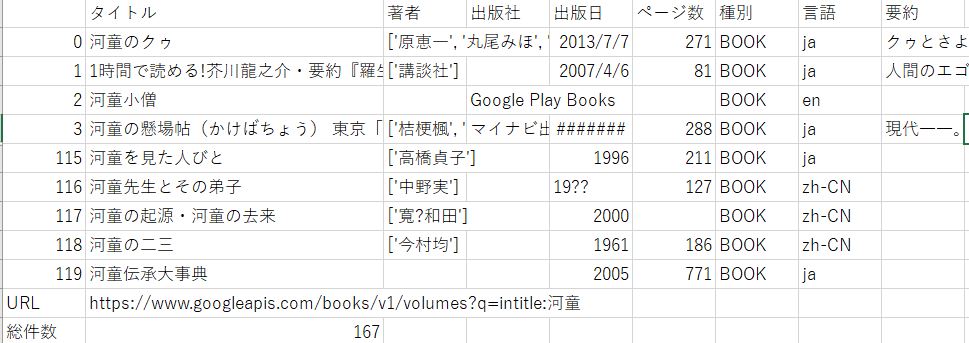
3回試行で120件取れているのでOKです。
気がかりなのは、総件数です。もともと209件ありましたが、最終的に167になっています。
これは、最終ループでの総件数を反映したものと思われますが、ズレが生じています。
startIndexが影響を与えている可能性がありますね。
では試行回数を増やすとどうなるでしょうか?試行回数を最大の6としてみます。
~~~~~略~~~~~
保存ファイル:kappa_test.csv
ファイル名OK? OK → y, No → any key:y
総件数:209、全取得に必要な試行回数:6
実行する試行回数を9以下の数字で入れてください。1~10以外で終了します。
実行する試行回数:6
~~~~~略~~~~~
items = items_list[i] #items
IndexError: list index out of rangeエラーがでました。
いろいろ試すと、最終ループで検索結果が40件を下回るため、おかしくなるようです。
itemリストの番号を固定値にせず、リストの長さを入れれば良さそうです。
~~~~~略~~~~~
def main(url, cycle):
~~~~~略~~~~~
items_list = response['items'] #items リストデータ
for i in range(len(items_list)): #取得件数 = 40
items = items_list[i] #items
~~~~~略~~~~~結果は略しますが、試行回数=4まではできました。
5以上でエラーが出ます。ただし先ほどのエラーとは異なります。
items_list = response['items'] #items リストデータ
KeyError: 'items'どうやら、5以上だと検索結果が0になっているようです。
なぜこうなるのか?というと、StartIndexを変えると検索の条件にも影響しており、総検索件数が変わるからと思われます。
ここはTry、exceptで回避したいと思います。
~~~~~略~~~~~
def main(url, cycle):
book_df = pd.DataFrame(index=[], columns=['タイトル', '著者',
'出版社', '出版日', 'ページ数', '種別', '言語', '要約'])
for c in range(cycle):
url_index = url+'&maxResults=40&startIndex='+str(c*40) #検索件数40, 開始index = 40*c
response = requests.get(url_index).json()
totalitems = response['totalItems'] #件数
try:
items_list = response['items'] #items リストデータ
except:
continue
for i in range(len(items_list)): #取得件数 = 40
~~~~~略~~~~~ではやってみましょう。
これで試行回数=6としてやってみましたが、エラーは出ませんでした!
では、出力されたCSVファイルを見てみましょう。
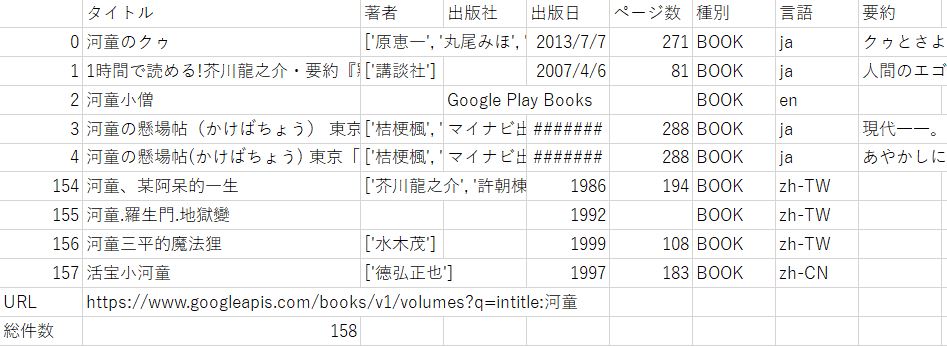
うまく出力されています。
総件数158となっており、実質4ループしかしていません。これはAPIの仕様上回避出来なさそうです。
ただし、158件全て取得できているのでOKとしましょう。
ここで、全検索結果の取得まではできました!!
残りやりたいのは、
③:保存用のCSVと解析用のCSVに分ける。
④:解析用CSVには、「要約」と検索URLを入れない。
です。
やることは、「データフレームから要約を削除」「解析用CSV作成」だけです。
データフレームから列を削除するんには、pandasの「drop」が使えます。
では、プログラムにしましょう。
追加は3行ですが、ここで最後なので全文を載せます。
import requests
import json
import pandas as pd
import csv
import sys
import time
""" input field """
""" 検索ワード入力 """
search = {
'free' : '', #free word
'title' : '河童',
'publisher' : '',
'subject' : '',
'isbn' : '',
'lccn' : '', #Library of Congress Control Number
'oclc' : '', #Online Computer Library Center number
}
""" 検索件数入力"""
#resurlt_num = 20 #全件検索の場合は未設定
""" 言語入力"""
lnaguage = '' #日本語なら'ja'入力
""" ソート入力"""
sort = '' #新しい順なら'newest'を入力。デフォルト(未入力)はrelevance
""" 出力csvファイル名入力"""
output_filename = 'kappa_test.csv' #.csv形式で名前を入力
""" input field 終了"""
def url_q():
title_q = '' if search['title']=='' else 'intitle:'+search['title']
publisher_q = '' if search['publisher']== '' else 'inpublisher:'+search['publisher']
subject_q = '' if search['subject']== '' else 'subject:'+search['subject']
isbn_q = '' if search['isbn']== '' else 'isbn:'+search['isbn']
lccn_q = '' if search['lccn']== '' else 'lccn:'+search['lccn']
oclc_q = '' if search['oclc']== '' else 'oclc:'+search['oclc']
q_list = [search['free'], title_q, publisher_q, subject_q, isbn_q, lccn_q, oclc_q]
q_list_2 = list(filter(None, q_list))
url_q = 'q=' + '+'.join(q_list_2)
return url_q
def url_generation():
base_url = 'https://www.googleapis.com/books/v1/volumes?'
#url_max = 'maxResults='+ str(resurlt_num) ここでは検索件数を設定しない
url_lnag = '' if lnaguage == '' else 'langRestrict='+lnaguage
url_sort = '' if sort == '' else 'orderBy='+sort
url_list = [url_q(), url_lnag, url_sort]
url_list_none = list(filter(None, url_list))
url = base_url + '&'.join(url_list_none)
return url
def first_search(url):
url_1st = url + '&maxResults=5'
response = requests.get(url_1st).json()
totalitems = response['totalItems'] #件数
book_df_1st = pd.DataFrame(index=[], columns=['タイトル', '著者'])
items_list = response['items']
for i in range(5):
items = items_list[i]
info = items.get('volumeInfo')
title = info.get('title')
author = info.get('authors')
book_df_1st = book_df_1st.append({'タイトル': title,
'著者' : author,}, ignore_index=True)
num_cycle = int(1 + (int(totalitems) / 40)) #試行回数 = 1 + 総件数/40
return totalitems, num_cycle, book_df_1st
def check(file_name, totalitems, num_cycle):
print('保存ファイル:'+file_name)
check_yn = input('ファイル名OK? OK → y, No → any key:')
if check_yn == 'y':
pass
else:
sys.exit()
print(f'総件数:{totalitems}、全取得に必要な試行回数:{num_cycle}')
print('実行する試行回数を9以下の数字で入れてください。1~10以外で終了します。')
while True:
inp_num_cycle = int(input('実行する試行回数:'))
if inp_num_cycle > num_cycle or inp_num_cycle > 10:
print('試行回数が多すぎます')
else:
return inp_num_cycle
break
def main(url, cycle):
book_df = pd.DataFrame(index=[], columns=['タイトル', '著者',
'出版社', '出版日', 'ページ数', '種別', '言語', '要約'])
for c in range(cycle):
url_index = url+'&maxResults=40&startIndex='+str(c*40) #検索件数40, 開始index = 40*c
response = requests.get(url_index).json()
totalitems = response['totalItems'] #件数
try:
items_list = response['items'] #items リストデータ
except:
continue
for i in range(len(items_list)): #取得件数 = 40
items = items_list[i] #items
info = items.get('volumeInfo')
title = info.get('title')
author = info.get('authors')
publisher = info.get('publisher')
publisheddate = info.get('publishedDate')
pages = info.get('pageCount')
printtype = info.get('printType')
description = info.get('description') #要約
language = info.get('language')
book_df= book_df.append({'タイトル': title,
'著者' : author,
'出版社' : publisher,
'出版日':publisheddate,
'ページ数':pages,
'種別':printtype,
'言語':language,
'要約':description}, ignore_index=True)
time.sleep(2)
book_df.to_csv(output_filename, encoding='CP932', errors = 'replace') #csvファイル出力, エラー置き換え
with open(output_filename, 'a', newline='') as f:
writer = csv.writer(f)
writer.writerow(['URL', url])
writer.writerow(['総件数', totalitems])
ana_df = book_df.drop('要約', axis=1) #良要約を削除
ana_file_name = 'analysis_'+output_filename #解析用のファイル
ana_df.to_csv(ana_file_name, encoding='CP932', errors = 'replace')
url = url_generation()
totalitems, num_cycle, book_df_1st = first_search(url)
print(url)
print(book_df_1st)
inp_num_cycle = check(output_filename, totalitems, num_cycle,)
main(url, inp_num_cycle)では見ていきましょう。エラーは出ません。
まず、フォルダに「analysis_kappa_test.csv」が生成されていました。
中身は以下です。
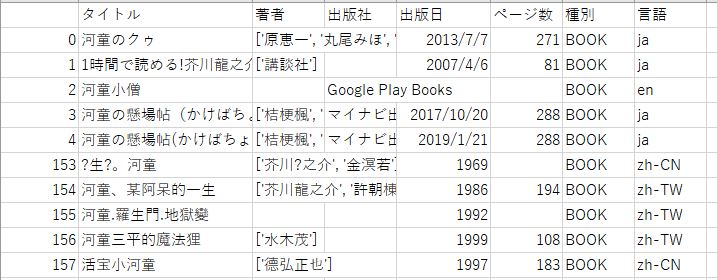
要約列がなくなっており、URL等の情報もありません。これで解析しやすい形のcsvファイルができました。
次回は出力されたファイルを解析していきましょう。
APIは多分使わなさそうです。
To Be Continued : Google Books APIを使ってみる ep4
PyQさんで勉強中!


コメント