
まずはAPIの使い方が分かった!
応用していこう!!
記事①:Pythonで検索してみよう ~Google Books APIを使ってみる ep1~
前回、Google Books APIを使ってまずは1冊の検索結果を出力しました。
ここでやりたいのは、
「APIを使って日本語のPython本の新刊情報を取得する」
です。
前回の内容を踏まえて、新刊情報の検索をやっていきます。
(2021年5月1日:学習開始71日目 PyQさんで勉強中!)
さて、APIと聞いて思い出すのは、スウェーデンのロックバンド A.C.Tです。
「複雑」かつ「ポップ」かつ「ハード」かつ「爽やか」かつ「ドラマチック」という離れ業をやってのけているのが、このA.C.Tです。
2021年2月に発売されたアルバム「Heatwave」から「Checked out」を聞きながらやっていきます。(曲名から公式YouTubeに飛びます。)
では、早速行きましょう!(完成プログラムは最後にあります。)
1.今回やりたいこと、前回の振り返り
冒頭にも書いた通り、今回やりたいのは、
「APIを使って日本語のPython本の新刊情報を取得する」
です。
実際に、AmazonでPythonと検索して日本語のみの新刊のみの情報を取るのは案外面倒でした。
そこで、Google Books APIを利用して、新刊検索をやっていこうと思います。
前回、Google Books APIs公式ページを読みながら、まずは1冊を検索して情報をアウトプットするプログラムを作りました。
出来たのが、以下です。
import requests
import json
url = 'https://www.googleapis.com/books/v1/volumes?q=isbn:9784798161914' #GooglBooksAPI
response = requests.get(url).json() #情報の取得,json変換
totalitems = response['totalItems'] #件数
items_list = response['items'] #items リストデータ
items = items_list[0] #items
info = items['volumeInfo']
title = info['title']
author = info['authors']
publisher = info['publisher']
publisheddate = info['publishedDate']
pages = info['pageCount']
printtype = info['printType']
description = info['description'] #要約
language = info['language']
print('件数:', totalitems)
print('タイトル:', title)
print('著者:', author)
print('出版社:', publisher)
print('出版日:', publisheddate)
print('ページ数:', pages)
print('種別:', printtype)
print('言語:', language)
print('要約:', description)
情報をとるところまでなら、実質4行で出来てしまっており、以降はデータをバラシて必要なものを抽出するプログラムです。
また、今回は標準外ライブラリとして「Requestsライブラリ」と「Pandasライブラリ」を使います。
インストールは前回記事参照。
では、これを参考に今回のプログラムを考えていきましょう。
2.今回やりたいこと、もう少し詳しく
やりたい事の概要は、上に書いたとおりですが、もう少し具体的に考えましょう。
イメージしているやりたい事、プログラムのイメージです。

ちなみに、「新しい順での情報取得」ですが、ここでは「新しい順で検索」としています。
やり方のアイデアとしては、「全数検索して新しい順に並べる」というのもあります。
実際、始めはこのやり方を考えていました。
しかし、
「Google Books APIはデフォルトで1検索あたり10件、拡張して40件までの検索しかできない」
という制限があります。(もっというと、1日1000件までだそうです。)
そのため、「新しい順に検索」という作戦を取っています。
APIは発行元の制限を受けるため自由度に限りがある。これがAPIの弱点かもしれません。
3.APIを使ってみよう① ~Python本検索~
では、プログラムに進みましょう。
まずAPIの正体をしりたいので、以下のプログラムを動かしてみます。
import requests
import json
url = 'https://www.googleapis.com/books/v1/volumes?q=Python' #GooglBooksAPI
response = requests.get(url).json() #情報の取得,json変換
print(response)非常に単純です。フリーワードでPythonと検索しました。
出力結果は以下です。かなり長いので、大きく端折っています。
{
"kind": "books#volumes",
"totalItems": 956,
"items": [
{
"kind": "books#volume",
"id": "XXXXX",
"etag": "p001ioFvrY0",
"selfLink": "https://www.googleapis.com/books/v1/volumes/XXXXX",
"volumeInfo": {
"title": "独習Python",
"authors": [
"山田祥寛"
],
"publisher": "翔泳社",
"publishedDate": "2020-06-22",
"description": "手を動かしておぼえるPythonプログラミング ~~~~~略~~~~~
"industryIdentifiers": [
{
"type": "ISBN_13",
~~~~~略~~~~~
"accessViewStatus": "SAMPLE",
"quoteSharingAllowed": false
},
"searchInfo": {
"textSnippet": "手を動かしておぼえるPythonプログラミング ~~~~~略~~~~~
}
},
{
"kind": "books#volume",
"id": "Ht-oDwAAQBAJ",
"etag": "/vE9mgkrqCg",
"selfLink": "https://www.googleapis.com/books/v1/volumes/XXXXX",
"volumeInfo": {
"title": "Pythonプロフェッショナルプログラミング 第2版",
"authors": [
"株式会社ビープラウド"
],
"publisher": "秀和システム",
"publishedDate": "2015-02-28",
~~~~~略~~~~~
}
},
{
"kind": "books#volume",
"id": "_ZLLDwAAQBAJ",
"etag": "8tUTOlsKkws",
"selfLink": "https://www.googleapis.com/books/v1/volumes/XXXXX",
"volumeInfo": {
"title": "PythonではじめるiOSプログラミング",
"authors": [
"掌田津耶乃"
],
~~~~~略~~~~~
}
},
~~~~~略~~~~~
}
}
]
}ややこしいので構成を見てみましょう。
{”kind”: “books#volumes”, “totalItems”: 956, “items”: [本のデータ]}
このようになっています。
まず、totalItemsで全件数が956件出ています。ただし、検索結果は10件だけ出力されています。
次いで、itemsに本のデータが格納されています
itemsの中身を見ていきましょう。
”items”:[{本①のデータ}, {本②のデータ},・・・{本⑩のデータ}]
要は、本のデータを取るには、
items[0]、items[1]・・・items[9]
とすれば良さそうです。ここから先は、前回の内容を使えばOKですね。
4.APIを使ってみよう② ~URL生成~
本格的にプログラムに進みましょう。
大きい構成として、
①:検索項目等の入力項目をまとめる
↓
②:①を反映したURLを作成する
↓
③:URLで問い合わせる
↓
④:データを抽出する
↓
⑤:Pandasでデータを表にまとめる
↓
⑥:データをCSVに出力する
というようにしたいと思います。
まずは、検索項目の入力です。Google Books APIs公式ページを見ていきます。
検索項目としては、
「自由ワード」「タイトル」「著者」「Subject(本のカテゴリー)」「ISBN」「LCCN」「OCLC」(後ろ3つは書籍、文献の識別番号です)
が挙げられています。
これらを入力できるようにしましょう。
""" input field """
""" 検索ワード入力 """
search = {
'free' : '', #free word
'title' : 'Python',
'publisher' : '',
'subject' : '',
'isbn' : '',
'lccn' : '', #Library of Congress Control Number
'oclc' : '', #Online Computer Library Center number
}searchという辞書型データでまとめました。
タイトルにのみPythonを入れています。
ほかのワードで検索したい場合、ここを変えればOKです。
また必要のない項目は「’’」で空文字列を入れるようにしています。
さらに公式ドキュメントを見ていくといろいろな項目があります。
全て反映すると相当長くなるので、今回反映させたい項目のみピックアップします。
反映させたいのは、「検索件数」「言語」「ソート」です。
では、プログラムに書きましょう。
~~~~~略~~~~~
""" 検索件数入力"""
resurlt_num = 5 #検索件数、未入力なら10
""" 言語入力"""
lnaguage = '' #日本語なら'ja'入力
""" ソート入力"""
sort = 'newest' #新しい順なら'newest'を入力。デフォルト(未入力)はrelevance
""" input field 終了"""入力項目はここまでです。
一旦、検索件数は5にしています。最後に増やしてみます。
次に、URLを設定していきます。
URLの構成はこのようになっています
https://www.googleapis.com/books/v1/volumes?q=(検索項目1)+(検索項目2)・・・&(その他項目)&(その他項目)
となっています。
つまり、「検索項目は+でつなぐ」「それ他の項目は&でつなぐ」必要があります。
(別途検証しましたが、適当にやっても一応検索はされます。ただ精度はかなり落ちます。)
では、「検索項目を+でつなぐ」をやりましょう。
公式ドキュメントを見ると、それぞれ書き方が決まっています。
例えば、「タイトル」であれば、「intitle:’検索したいタイトル’」のような構成にする必要があります。
さらにそれらを「+」でつないで、「q=」と接続します。
ではプログラムを書いてみましょう。
~~~~~略~~~~~
""" input field 終了"""
def url_q():
title_q = 'intitle:'+search['title']
publisher_q = 'inpublisher:'+search['publisher']
subject_q = 'subject:'+search['subject']
isbn_q = 'isbn:'+search['isbn']
lccn_q = 'lccn:'+search['lccn']
oclc_q = 'oclc:'+search['oclc']
q_list = [search['free'], title_q, publisher_q, subject_q, isbn_q, lccn_q, oclc_q]
url_q = 'q=' + '+'.join(q_list) #q= と各検索項目を+でつなぐ
return url_q
print(url_q())これで出力してみましょう。
q=+intitle:Python+inpublisher:+subject:+isbn:+lccn:+oclc:まあ、予想していましたがこうなりますね。
実際これでも検索は可能です。Goodleヤバい。ただしやはり精度は落ちます。
という事で、inputで入力されていない項目は空のままにしてみましょう。
ifを使って、以下のように書けば出来そうです。
if search['title'] == '':
title_q = ''
else:
title_q = 'intitle:'+search['title']これで書けます。ただし、全てでやると相当長くなります。
調べてみると、この程度のif文であれば1行表示が出来るようです。
title_q = '' if search['title']=='' else 'intitle:'+search['title']これを他の項目でも反映させましょう。
~~~~~略~~~~~
""" input field 終了"""
title_q = '' if search['title']=='' else 'intitle:'+search['title']
publisher_q = '' if search['publisher']== '' else 'inpublisher:'+search['publisher']
subject_q = '' if search['subject']== '' else 'subject:'+search['subject']
isbn_q = '' if search['isbn']== '' else 'isbn:'+search['isbn']
lccn_q = '' if search['lccn']== '' else 'lccn:'+search['lccn']
oclc_q = '' if search['oclc']== '' else 'oclc:'+search['oclc']
q_list = [search['free'], title_q, publisher_q, subject_q, isbn_q, lccn_q, oclc_q]
url_q = 'q=' + '+'.join(q_list) #q= と各検索項目を+でつなぐ
return url_q
print(url_q())では出力してみましょう。
q=+intitle:Python+++++うわ~、+++++++
うまく空にはできましたが、空の項目も認識されて+でつないでしまっています。
空の項目をパスしたいですね。
いろいろ調べると、filter関数が使えるようです。(参考:filter(None,list)の動作)
本来であればfilter(x, list)とすれば、listからx=Trueとなる要素を抽出します。
しかし、xにNoneを入れた場合は、Noneを除外するようです。これはかなり特殊!
これを使ってみましょう!!
~~~~~略~~~~~
""" input field 終了"""
def url_q():
title_q = '' if search['title']=='' else 'intitle:'+search['title']
publisher_q = '' if search['publisher']== '' else 'inpublisher:'+search['publisher']
subject_q = '' if search['subject']== '' else 'subject:'+search['subject']
isbn_q = '' if search['isbn']== '' else 'isbn:'+search['isbn']
lccn_q = '' if search['lccn']== '' else 'lccn:'+search['lccn']
oclc_q = '' if search['oclc']== '' else 'oclc:'+search['oclc']
q_list = [search['free'], title_q, publisher_q, subject_q, isbn_q, lccn_q, oclc_q]
q_list_none = list(filter(None, q_list))
url_q = 'q=' + '+'.join(q_list_none) #q= と各検索項目を+でつなぐ
return url_q
print(url_q())ではアウトプットしてみましょう。
q=intitle:Python出来ました!!
これだけですが、なかなか苦戦しますね。
では次に行きましょう。次はURLの生成です。
ベースのURLと、先ほど生成した「url_q」と「その他項目」を「&」でつなぎます。
「その他項目」もそれぞれ適切な書き方があるので、形式を変換します。
ここまでやった、if文、filterを応用すれば、簡単ですね。
~~~~~略~~~~~
def url_q():
~~~~~略~~~~~
def url_generation():
base_url = 'https://www.googleapis.com/books/v1/volumes?'
url_max = 'maxResults='+ str(resurlt_num)
url_lnag = '' if lnaguage == '' else 'langRestrict='+lnaguage
url_sort = '' if sort == '' else 'orderBy='+sort
url_list = [url_q(), url_max, url_lnag, url_sort]
url_list_none = list(filter(None, url_list))
url = base_url + '&'.join(url_list_none)
return url
print(url_generation())結果はこうなりました。
https://www.googleapis.com/books/v1/volumes?q=intitle:Python&maxResults=5&orderBy=newestURL生成できました!!
5.APIを使ってみよう③ ~Python最新本検索~
では、できたURLを使って検索してみましょう。
一旦、前回つくったプログラムをまるっと持ってきましょう。ほぼ丸写しです。
import requests
import json
""" input field """
""" 検索ワード入力 """
~~~~~略~~~~~
def url_q():
~~~~~略~~~~~
def url_generation():
~~~~~略~~~~~
def main(url):
response = requests.get(url).json()
totalitems = response['totalItems'] #件数
items_list = response['items'] #items リストデータ
items = items_list[0] #items
info = items['volumeInfo']
title = info['title']
author = info['authors']
publisher = info['publisher']
publisheddate = info['publishedDate']
pages = info['pageCount']
printtype = info['printType']
description = info['description'] #要約
language = info['language']
print('件数:', totalitems)
print('タイトル:', title)
print('著者:', author)
print('出版社:', publisher)
print('出版日:', publisheddate)
print('ページ数:', pages)
print('種別:', printtype)
print('言語:', language)
print('要約:', description)
url = url_generation()
main(url)では出力してみましょう。
件数: 499
タイトル: Programming the Raspberry Pi, Third Edition: Getting Started with Python
著者: ['Simon Monk']
出版社: McGraw-Hill Education TAB
出版日: 2021-06-04
ページ数: 192
種別: BOOK
言語: en
要約: An up-to-date guide to ~~~~~略~~~~~英語の本ですね。今のところ、言語選択はあえてしていないので、これでいいです。
2021/6/4発刊です。最新本ですね。近づいてまいりました。
それにしても
「Programming the Raspberry Pi, Third Edition: Getting Started with Python」
気になりますね。
これは、1件目が出力されています。リストの[0]番が選択されているためです。
では試しにリストの1番(2件目)を出力してみましょう。
件数: 499
タイトル: お仕事Python
著者: ['日経ソフトウエア']
出版社: 日経BP
出版日: 2021-04-14
ページ数: 180
種別: BOOK
言語: ja
要約: ※この商品はタブレットなど大きいディスプレイを備えた端末で読むことに適しています。~~~~~略~~~~~次は日本の本です。これは2021/4/14です。「お仕事python」これも気にります。
さて、一気にデータを取りたいので、for文で回しましょう。
回数は、検索件数と合わせれば良さそうですね。
import requests
import json
""" input field """
""" 検索ワード入力 """
~~~~~略~~~~~
def url_q():
~~~~~略~~~~~
def url_generation():
~~~~~略~~~~~
def main(url, num):
response = requests.get(url).json()
totalitems = response['totalItems'] #件数
print('件数:', totalitems)
items_list = response['items'] #items リストデータ
for i in range(num):
items = items_list[i] #items
info = items['volumeInfo']
title = info['title']
author = info['authors']
publisher = info['publisher']
publisheddate = info['publishedDate']
pages = info['pageCount']
printtype = info['printType']
description = info['description'] #要約
language = info['language']
print('タイトル:', title)
print('著者:', author)
print('出版社:', publisher)
print('出版日:', publisheddate)
print('ページ数:', pages)
print('種別:', printtype)
print('言語:', language)
print('要約:', description)
url = url_generation()
main(url, resurlt_num)件数: 499
タイトル: Programming the Raspberry Pi, Third Edition: Getting Started with Python
著者: ['Simon Monk']
出版社: McGraw-Hill Education TAB
~~~~~略~~~~~
タイトル: お仕事Python
著者: ['日経ソフトウエア']
~~~~~略~~~~~
要約: ※この商品はタブレットなど大きいディスプレイを備えた端末で読むことに適しています。~~~~~略~~~~~
Traceback (most recent call last):
File "c:/Users/XXXXX.py", line 71, in <module>
main(url, resurlt_num)
File "c:/Users/XXXXX.py", line 57, in main
pages = info['pageCount']
KeyError: 'pageCount'エラーがでました。3冊目です。どうやら、元データにページに関する情報がなかったようです。
ここで、いろいろ調べるとget関数という便利なものがあります。
これは、
{辞書}.get(key)のように使って、keyがあればvalueを返す、keyがなければNoneを返します。
では、編集しましょう。
import requests
import json
""" input field """
""" 検索ワード入力 """
~~~~~略~~~~~
def url_q():
~~~~~略~~~~~
def url_generation():
~~~~~略~~~~~
def main(url, num):
response = requests.get(url).json()
totalitems = response['totalItems'] #件数
print('件数:', totalitems)
items_list = response['items'] #items リストデータ
for i in range(num):
items = items_list[i] #items
info = items.get('volumeInfo')
title = info.get('title')
author = info.get('authors')
publisher = info.get('publisher')
publisheddate = info.get('publishedDate')
pages = info.get('pageCount')
printtype = info.get('printType')
description = info.get('description') #要約
language = info.get('language')
print('タイトル:', title)
print('著者:', author)
print('出版社:', publisher)
print('出版日:', publisheddate)
print('ページ数:', pages)
print('種別:', printtype)
print('言語:', language)
print('要約:', description)
url = url_generation()
main(url, resurlt_num)出力結果です。
件数: 499
タイトル: Programming the Raspberry Pi, Third Edition: Getting Started with Python
著者: ['Simon Monk']
出版社: McGraw-Hill Education TAB
~~~~~略~~~~~
タイトル: 図解! Pythonのツボとコツがゼッタイにわかる本 プログラミング実践編
著者: ['立山秀利']
出版社: 秀和システム
出版日: 2021-03-26
ページ数: None
種別: BOOK
言語: ja
~~~~~略~~~~~エラーは出ていません。これでOKです。
3冊目の本のページ数はNoneとなってますね。やはり元データがなかったようです。
これでデータの回収まではできましたね。
6.APIを使ってみよう④ ~データをPandasにまとめて出力~
では、ここからデータをまとめていきましょう。
Pandasでデータを表の形にしていきます。
表の「カラム」はすでに決まっている(さっき出力した項目)ので、空のデータフレームを作ります。
続いて、for文の中でデータを入れていきます。(さっきのprintは不要ですね)
あまり難しくはなさそうですね。
ちなみに、ここから「検索件数=20」、「検索言語=日本語」としていきます。
import requests
import json
import pandas as pd
""" input field """
""" 検索ワード入力 """
~~~~~略~~~~~
def url_q():
~~~~~略~~~~~
def url_generation():
~~~~~略~~~~~
def main(url, num):
response = requests.get(url).json()
totalitems = response['totalItems'] #件数
print('件数:', totalitems)
book_df = pd.DataFrame(index=[], columns=['タイトル', '著者',
'出版社', '出版日', 'ページ数', '種別', '言語', '要約']) #Data Frame作成
items_list = response['items'] #items リストデータ
for i in range(num):
~~~~~略~~~~~
language = info.get('language')
book_df= book_df.append({'タイトル': title,
'著者' : author,
'出版社' : publisher,
'出版日':publisheddate,
'ページ数':pages,
'種別':printtype,
'言語':language,
'要約':description}, ignore_index=True)
print(book_df)出力結果です。途中はカットしています。
件数: 341
タイトル 著者 出版社 出版日 ページ数 種別 言語
要約
0 お仕事Python [日経ソフトウエア] 日経BP 2021-04-14 180 BOOK ja ※この商品はタブレットなど大きいディスプレイを備えた端
末で読むことに適しています。また、文字...
19 ゼロから学ぶPythonプログラミング Google Colaboratoryでらくらく導入 [渡辺宙志] 講談社 2020-12-17 256 BOOK ja 【初学者納得
、玄人脱帽!】 SNSで大絶賛の名講義がついに書籍化! ・問題解決に必要な「プロ...データを欲張りすぎて文字が切れていますが、表記だけの問題だと思うのでおそらく大丈夫です。
ではデータフレームをCSVファイルで出力しましょう。
まず、CSVファイル名は入力パートで決めましょう。
で、最後にCSVファイルに出力しましょう。
import requests
import json
import pandas as pd
""" input field """
""" 検索ワード入力 """
~~~~~略~~~~~
""" 出力csvファイル名入力"""
output_filename = 'python_ja_new.csv' #.csv形式で名前を入力
""" input field 終了"""
~~~~~略~~~~~
def main(url, num):
~~~~~略~~~~~
book_df.to_csv(output_filename)
url = url_generation()
main(url, resurlt_num)出力してみます。
現在作成しているプログラムファイル(~~~~.py)と同じところに
「python_ja_new.csv」
が出来ています。
Excelで開いてみます。
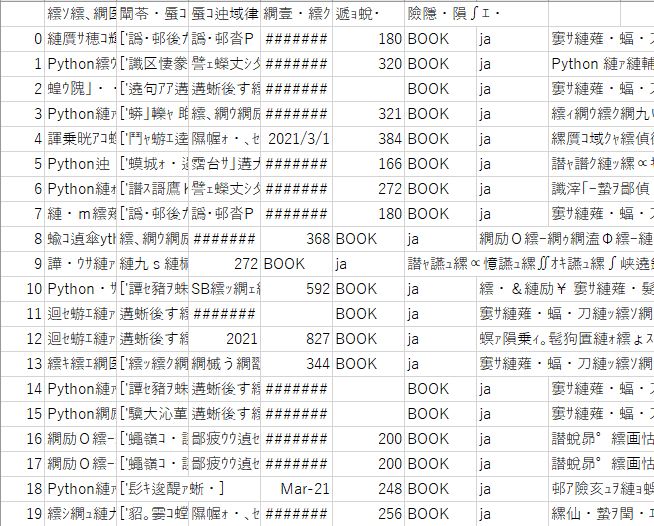
あちゃ~、めちゃくちゃですね。
出来ている点は、20個のデータが出力されている事くらいです。
まずは文字化けをなんとかしましょう。
しかし、この感じは経験があるので対処できます。文字のコードの問題ですね。
ローカルとweb上のcsvファイルを読み込む ~Pythonで百人一首クイズを作ろう ep 1~
これを踏まえて、csvファイルを書き込みのコードを編集しましょう。
(今回、encodingはCP932にしています。よく使うShift-Jisでは\u2460=①が読めずにエラーになりました。)
import requests
import json
import pandas as pd
""" input field """
""" 検索ワード入力 """
~~~~~略~~~~~
book_df.to_csv(output_filename, encoding='CP932') #csvファイル出力
url = url_generation()
main(url, resurlt_num)結果です。
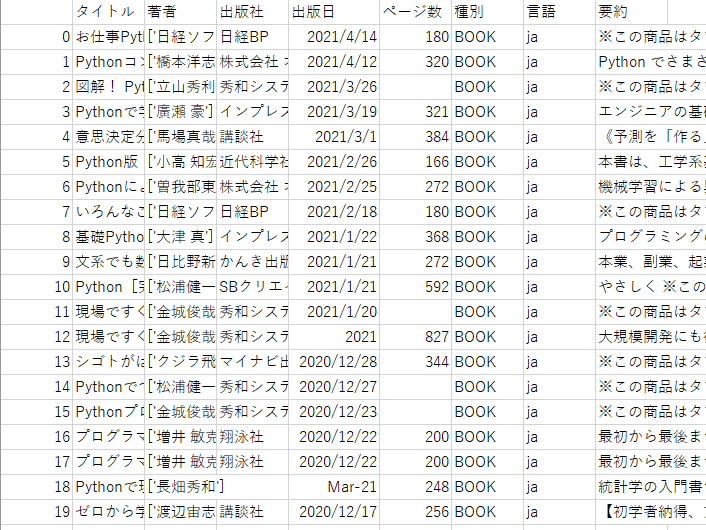
うまくいけましたね。全て日本語の書籍が抽出できています。
要約まできちんと出来ています。
最後に、検索URLと総件数をCSVファイルに記録しましょう。
CSVライブラリを使えば簡単に書けます。
また、せっかくなので、これまではタイトル=Pythonの本を調べましたが、フリーワード=Pythonの本を調べてみましょう。
これで最後ですので、全プログラムを書いておきます。
import requests
import json
import pandas as pd
import csv
""" input field """
""" 検索ワード入力 """
search = {
'free' : 'Python', #free word
'title' : '',
'publisher' : '',
'subject' : '',
'isbn' : '',
'lccn' : '', #Library of Congress Control Number
'oclc' : '', #Online Computer Library Center number
}
""" 検索件数入力"""
resurlt_num = 20 #検索件数、未入力なら10
""" 言語入力"""
lnaguage = 'ja' #日本語なら'ja'入力
""" ソート入力"""
sort = 'newest' #新しい順なら'newest'を入力。デフォルト(未入力)はrelevance
""" 出力csvファイル名入力"""
output_filename = 'free_word_python_ja_new.csv' #.csv形式で名前を入力
""" input field 終了"""
def url_q():
title_q = '' if search['title']=='' else 'intitle:'+search['title']
publisher_q = '' if search['publisher']== '' else 'inpublisher:'+search['publisher']
subject_q = '' if search['subject']== '' else 'subject:'+search['subject']
isbn_q = '' if search['isbn']== '' else 'isbn:'+search['isbn']
lccn_q = '' if search['lccn']== '' else 'lccn:'+search['lccn']
oclc_q = '' if search['oclc']== '' else 'oclc:'+search['oclc']
q_list = [search['free'], title_q, publisher_q, subject_q, isbn_q, lccn_q, oclc_q]
q_list_2 = list(filter(None, q_list))
url_q = 'q=' + '+'.join(q_list_2)
return url_q
def url_generation():
base_url = 'https://www.googleapis.com/books/v1/volumes?'
url_max = 'maxResults='+ str(resurlt_num)
url_lnag = '' if lnaguage == '' else 'langRestrict='+lnaguage
url_sort = '' if sort == '' else 'orderBy='+sort
url_list = [url_q(), url_max, url_lnag, url_sort]
url_list_none = list(filter(None, url_list))
url = base_url + '&'.join(url_list_none)
return url
def main(url, num):
response = requests.get(url).json()
totalitems = response['totalItems'] #件数
print('件数:', totalitems)
book_df = pd.DataFrame(index=[], columns=['タイトル', '著者',
'出版社', '出版日', 'ページ数', '種別', '言語', '要約']) #Data Frame作成
items_list = response['items'] #items リストデータ
for i in range(num):
items = items_list[i] #items
info = items.get('volumeInfo')
title = info.get('title')
author = info.get('authors')
publisher = info.get('publisher')
publisheddate = info.get('publishedDate')
pages = info.get('pageCount')
printtype = info.get('printType')
description = info.get('description') #要約
language = info.get('language')
book_df= book_df.append({'タイトル': title,
'著者' : author,
'出版社' : publisher,
'出版日':publisheddate,
'ページ数':pages,
'種別':printtype,
'言語':language,
'要約':description}, ignore_index=True)
print(book_df)
book_df.to_csv(output_filename, encoding='CP932') #csvファイル出力
with open(output_filename, 'a', newline='') as f:
writer = csv.writer(f)
writer.writerow(['URL', url])
writer.writerow(['総件数', totalitems])
url = url_generation()
main(url, resurlt_num)
出力結果は以下です。
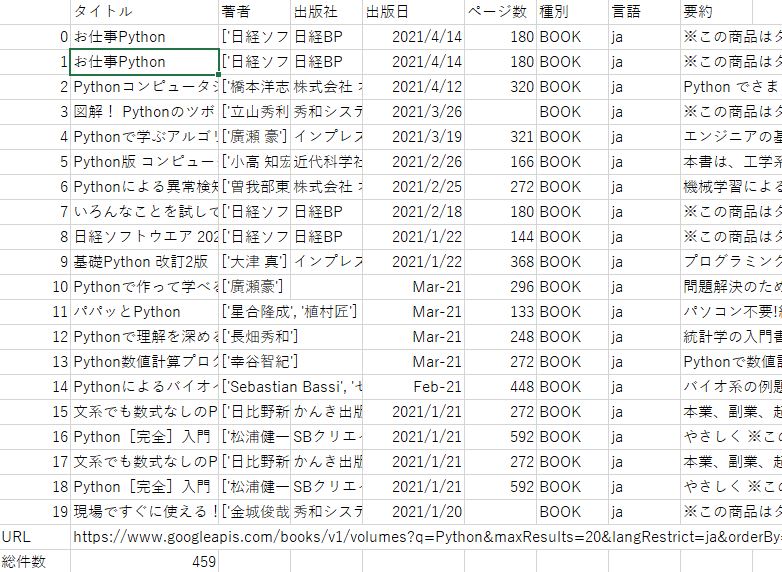
URLと総件数も出力されていますね。これで完成です。
なお、フリーワードの検索の方が検索結果は多くなりますが、カブりも出てくるようです。
次回は、単純な本の検索から離れて、もう少し遊んでみたいと思います。
To Be Continued : Google Books APIを使ってみる ep3
PyQさんで勉強中!


コメント