
なんかクイズゲーム的なものを作ってみたい。
そうだ、百人一首だ!!
今回から、また新たなものを作りたいと思います。
今の知識でなんとなくクイズゲーム的なものがつくれそうな気がします。
で、どんなクイズにするかって話ですが、
①:数理系クイズ(数学の知識で説くクイズ、知識はあんまりいらないヤツ)
②:知識系クイズ(知識で正誤判定するクイズ)
③:ひらめき系クイズ(特別な知識不要で)
がパッと思い付きました。
①の数理系クイズは、ちょっと気分じゃないのではパスです!
(前回、モンティホールやりすぎたので・・・)
③のひらめき系クイズは、今の知識では作り方のイメージが出来ません。
(というか、よく考えると1つ1つ問題を用意する必要あるよねぇ。出題側視点では知識系クイズと同じになるのかも・・)
ということで、今回は知識系クイズを作ります!
ここで問題になるのが、知識の集約です。
問題数は多くなる方が、プログラミング的にもクイズ的にも楽しいと思うので、たくさんの「知識」が集めたいです。
それと、これはブログ上の問題ですが、公開するなら著作権フリーの知識がいいです。
あと、裏テーマ(本来の表テーマですが・・・)として、「オブジェクト指向」と「class」を学びたいというのがあります。つまり、ある程度型がきまった問題の方がよいと思っています。
そうだ、「百人一首」があるじゃないか!
「問題数100問」十分です。
「作者死後70年以上たっているので著作権フリー」の「和歌(=型が決まっている)」。
「百人一首クイズ」で行きましょう!
(2021年3月26日:学習開始35日目気づけば1か月続いている!!PyQさんで勉強中!)
「百人一首」といえば映画「ちはやふる」が思い出されます。
原作はマンガですが、未読なので私は広瀬ずずさん主演の映画のイメージです。
これが、めちゃ熱いんですよ。未見の方はぜひ見てほしいです。
こんなんで大の大人が泣くわけ無い・・・うわ(泣)~~~行け~~~ってなるんですよね。
で、その1作目(上の句)の主題歌がPerfumeさんの「FLASH」でした。
(曲名から公式YouTubeに飛びます。)
聞きながら映画を思い出しつつ、今回はやっていこうと思います。
さあ、それでは行きましょう。
(今回は、クイズの概要とcsvファイルの取得に終始します。初めてのwebスクレイピングに成功します。)
1.どんなクイズにする?
まず、どんなものを作るか具体的なイメージを考えていきます。
少しお勉強しましょう。
「百人一首」は100人の歌人の和歌を一人につき一首ずつ選んだ和歌集です。
実はいろんな種類があるそうですが、一般的に「百人一首」と呼ばれているのは、藤原定家が京都・小倉山で選んだとされる「小倉百人一首」を指します。
今回は例にもれず、この「小倉百人一首」を使います。
そしてもう一つ「百人一首」でイメージされるもの、「かるた取り」ですね。
一般的なルールでは、下の句がとり札になっていて、読み手は上の句→下の句と読んでいきます。
私のような素人は、下の句が読まれて初めて札を取れるわけですが、競技かるたではプレイヤー=競技者は百首すべてを暗記しており、上の句が読まれた瞬間に下の句をとる争いになるわけです。
(もっというと、1文字、2文字、3文字まで読まれた瞬間で決着がつきますが、ここではパス)
今回は、この「かるた取り」を再現するようなゲームにしたいと思います。
つまり、「上の句が出題」で、「下の句が答え」のクイズです。
つぎにクイズの方のイメージを考えていきます、
出題は、「上の句」一つがランダムに表示されれば良いと思います。
では、解答はどうするか?いったん私のアイデアは2つです。
解答アイデア①:「下の句」を打ち込む
解答アイデア②:「下の句」が複数個ランダムで表示され、正解を選ぶ。
どちらもプログラミングで再現できそうですが、②の方がよさそうです。
打ち込むの大変なのと、正確に書くと「ゑ」とか「ゐ」とかもあるので、たぶん大変です。
下の句は選択肢が多い方がクイズとしては難しくなりますが、ここではいったん選択肢を5個にしたいと思います。つまり下の句は正解1つ+不正解ランダムに4つが表示されるわけです。
それともう一つ、かるた取りは、正解するとかるたがなくなっていきます。
ですので、一度正解した問題=「上の句」は再登場しないようなクイズにしたいと思います。
一方、「下の句」についてはクイズ性をあげるため、常に100首から5首が選ばれるようにしたいと思います。
これでかなり、具体的なイメージがまとまったと思います。
今回作りたいゲームはこんな感じです。

こんな感じにしてみました。なんかゲームっぽくなってきましたね。
2.百人一首をGETしよう ~百人一首みつけたり~
これまでは、大体作りたいものが見えたところで、フローチャートを書いていました。
しかし、現時点では私はまだプログラミングの全体像が見えていません。
今回は、先に百人一首を取得するところから始めて、その後に全体像を考えていきたいと思います。
では、どうやって百人一首をGETしましょうか。
いろいろ探しているといいものを見つけました。
GitHubの小倉百人一首.csvというものがありました。誰でも自由に使ってよいと書いてありますので、ありがたく使わせていただきます。
さて、百人一首はみつかりました。
では、どのように使っていくか。2つのやり方が考えられます。
①:csvファイルを自分のPCにダウンロードし、ローカル(PC内)のファイルにアクセスする。
②:web上のデータに直接アクセスし、データを取得する。
今回は①の方(csvダウンロードしてローカル実行)を選択したいと思います。
理由は、
「もし今後web上から消されても手元にダウンロードしておけば問題なく使用できる」
「毎回アクセスするのでオンラインでしか使えない」
(「毎回アクセスすると若干ではあるが回線上に負荷を与えるので迷惑な気がする・・・」)
しかし、②もやってみたい・・・そうだ、WEBスクレイピングだ!
そもそも、Pythonの練習だぞ、やるしかないでしょう!!!
ということで、今回は、最終的には①のプログラムで進めますが、さきに①と②の両方でデータ取得するところまではやってみます。
3.データ読み込み① ~ローカルcsvファイル読み込みけり~
ローカルcsvファイルの読み込みからやってみましょう。
まず、ローカルにファイルをダウンロードするところからです。
先ほどのGitHub小倉百人一首.csvにアクセスして緑色の「Code」をクリックし「Download ZIP」からダウンロードできます。
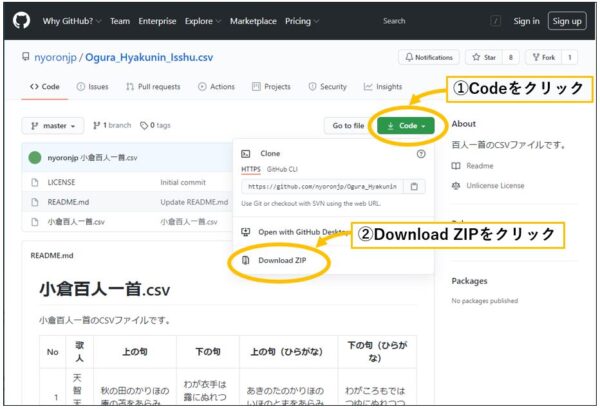
ダウンロードしたZIPファイルを解凍し、「小倉百人一首.csv」を好きなフォルダに置くと準備完了です。ちなみに、私は、csvファイルの名前を「hyakunin.csv」という名前に変えています。
では、プログラミングを書いていきましょう。
with open('C:/Users/xxxx/yyyy/hyakunin.csv', 'r', encoding = 'utf-8') as f: #「hyakunin.csv」を開く
for row in f:
print(row)結果このようになりました。
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x89 in position 3: invalid start byteutf-8がなんかダメっぽいです、、、ここってつまり、文字の形式を決めるとこだと思うのですが、弾かれたようです。
確かに、百人一首って「ゑ」とかあるし、そういうこともあるのかと思います。(原因わかりませんが・・)
そこで、調べてみると解説してくれてる方がいました。(UnicodeDecodeErrorの原因と対処法【Python】)
やはり詳しい方がいるもんですね。これにならってutf-8をshift_jisに変えてみましょう。
with open('C:/Users/xxxx/yyyy/hyakunin.csv', 'r', encoding='shift_jis') as f:
for row in f:
print(row)では実行してみましょう。
No,歌人,上の句,下の句,上の句(ひらがな),下の句(ひらがな)
1,天智天皇,秋の田のかりほの庵の苫をあらみ,わが衣手は露にぬれつつ,あきのたのかりほのいほのとまをあらみ,わがころもではつゆにぬれつつ
2,持統天皇,春過ぎて夏来にけらし白妙の,衣干すてふ天の香具山,はるすぎてなつきにけらししろたへの,ころもほすてふあまのかぐやま
~~~~略~~~~
98,従二位家隆,風そよぐ楢の小川の夕暮は,みそぎぞ夏のしるしなりける,かぜそよぐならのをがはのゆふぐれは,みそぎぞなつのしる しなりける
99,後鳥羽院,人もをし人もうらめしあじきなく,世を思ふゆゑにもの思ふ身は,ひともをしひともうらめしあぢきなく,よをおもふゆゑ にものおもふみは
100,順徳院,百敷や古き軒端のしのぶにも,なほあまりある昔なりけり,ももしきやふるきのきばのしのぶにも,なほあまりあるむかしなりけり
うまく取れています。
では、この後の使用を考えて、それぞれリストにいれるのと、「 , 」で分かれるようにしましょう。
with open('C:/Users/xxxx/yyyy/hyakunin.csv', 'r', encoding='shift_jis') as f:
for row in f:
print(row.strip().split(','))では再度実行してみましょう。
['No', '歌人', '上の句', '下の句', '上の句(ひらがな)', '下の句(ひらがな)']
['1', '天智天皇', '秋の田のかりほの庵の苫をあらみ', 'わが衣手は露にぬれつつ', 'あきのたのかりほのいほのとまをあらみ', ' わがころもではつゆにぬれつつ']
['2', '持統天皇', '春過ぎて夏来にけらし白妙の', '衣干すてふ天の香具山', 'はるすぎてなつきにけらししろたへの', 'ころもほ すてふあまのかぐやま']
~~~~略~~~~
['98', '従二位家隆', '風そよぐ楢の小川の夕暮は', 'みそぎぞ夏のしるしなりける', 'かぜそよぐならのをがはのゆふぐれは', 'みそぎぞなつのしるしなりける']
['99', '後鳥羽院', '人もをし人もうらめしあじきなく', '世を思ふゆゑにもの思ふ身は', 'ひともをしひともうらめしあぢきなく', 'よをおもふゆゑにものおもふみは']
['100', '順徳院', '百敷や古き軒端のしのぶにも', 'なほあまりある昔なりけり', 'ももしきやふるきのきばのしのぶにも', 'なほ あまりあるむかしなりけり']うまく行きましたね!!
いったん、ここでSTOPしましょう。
4.データ読み込み② ~Webスクレイピングをやりにけり~
ローカルにダウンロードしたcsvファイルは無事にインプットすることができました。
では、次にWeb上にあるcsvファイルをそのまま取得してみましょう。
Webスクレイピングです!!
これはPythonって何ができるのか?って調べると書いてあるなかの一つにだいたい「Web上の画像・テクストデータの収集」見たいなことが挙げられていると思います。
これがwebスクレイピングです。今回、これをやってみたいと思います。
今回は、このページを小倉百人一首.csvを取得したいと思います。
web上の普通のページ(htmlのページ)ではなく、web上のcsvの取得です。
(ページのアドレスの最後が「 .csv 」となっています。)
では、プログラムを書いていきましょう。
実は、PyQさんで学んだコードのほぼコピペになります。
細かくは理解しきれていない部分もあります。
注意!:私はanacondaを使っているので今回使うすべてのモジュールをインストール済みの状態です。公式のPythonを使用している場合インストールされていないのでモジュールをインストールがする必要があります。下記のようなコードでインストールできます。
なお、csvとioモジュールは最初からインストールされています。
pip install requests #requestsモジュールのインストールさて、プログラミングを書いていきましょう。
ここで使うモジュールは、「csv」「StringIO」「requests」の3つです。
urlはそのまま記載せずに省略した形としています。
実際に実行する場合は、該当ページのURLを書くようにしましょう。(ただし下記は失敗します。)
import csv #csvモジュールのインポート
from io import StringIO #StringIOモジュールのインポート
import requests
url = "https://github~~~~略~~~~~.csv"
response = requests.get(url) #urlにリクエストを送信してcsvを取得する
response.encoding = response.apparent_encoding
#apparent_encodingは文字エンコードをチェックし適切なエンコードを返す。
#response.encodingに適切なエンコードを設定する事で文字化けを防止
reader = csv.reader(StringIO(response.text))
#.textでテキスト形式で取得。
#StringIOでテキスト(文字列)をファイルオブジェクトに
#csv.readerでファイルオブジェクトを解析
for row in reader:
print(row)結果、このようになりました。
[]
[]
[]
[]
[]
[]
['<!DOCTYPE html>']
['<html lang="en" >']
[' <head>']
[' <meta charset="utf-8">']
[' <link rel="dns-prefetch" href="https://github.githubassets.com">']
[' <link rel="dns-prefetch" href="https://avatars.githubusercontent.com">']
[' <link rel="dns-prefetch" href="https://github-cloud.s3.amazonaws.com">']
~~~~~~略~~~~~~~
' <div class="Popover js-hovercard-content position-absolute" style="display: none; outline: none;" tabindex="0">']
[' <div class="Popover-message Popover-message--bottom-left Popover-message--large Box color-shadow-large" style="width:360px;">']
[' </div>']
['</div>']
[]
[]
[]
[]
[' </body>']
['</html>']
[]非常に長いですが、途中に百人一首の中身もあります。
しかし、思っていたのと違います。
で、こういう場合はやっぱり検索です。なぜこのようになったのでしょうか?
こちらに答えがありました。
【初心者向け】ColaboratoryでCSVを読み込む最も簡単な方法 ⇒ Pandas (+Github)
メインの内容は、「Web上にあるCSVファイルはpandasを利用すると実質1行でデータをインポート可能」というこれまた非常に気になる内容ですが(後ほど実行してみます)、ページ下部の注意点として、
GitHubからcsvをインポートする「Raw」を利用するとあります。
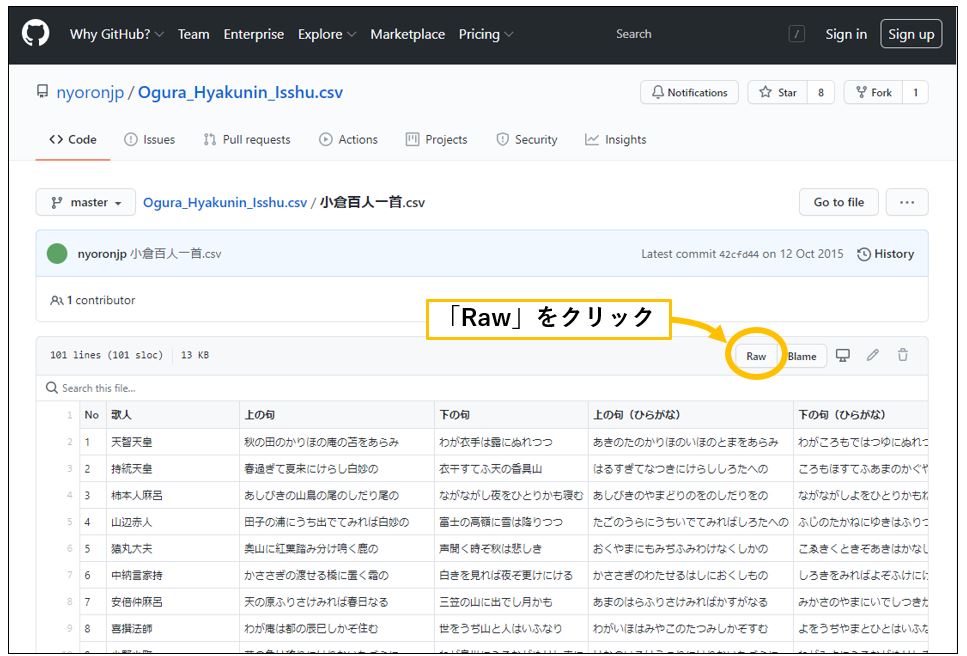
すると文字化けしまくったヤバいページが開きました。
私だけでしょうか?またこれでいけるのでしょうか?

非常に不安ですが、このURLをコピーして先のプログラムのurlを変更して実行しました。
(ちなみにURL中の「小倉百人一首」という日本語は、コピペすると%E5%B0%8F%E5%80%8~みたいになりますが、それでOKでした。)
['No', '歌人', '上の句', '下の句', '上の句(ひらがな)', '下の句(ひらがな)']
['1', '天智天皇', '秋の田のかりほの庵の苫をあらみ', 'わが衣手は露にぬれつつ', 'あきのたのかりほのいほのとまをあらみ', 'わがころもではつゆにぬれつつ']
['2', '持統天皇', '春過ぎて夏来にけらし白妙の', '衣干すてふ天の香具山', 'はるすぎてなつきにけらししろたへの', 'ころもほすてふあまのかぐやま']
~~~~~略~~~~~
['98', '従二位家隆', '風そよぐ楢の小川の夕暮は', 'みそぎぞ夏のしるしなりける', 'かぜそよぐならのをがはのゆふぐれは', 'みそぎぞなつのしるしなりける']
['99', '後鳥羽院', '人もをし人もうらめしあじきなく', '世を思ふゆゑにもの思ふ身は', 'ひともをしひともうらめしあぢきなく', 'よをおもふゆゑにものおもふみは']
['100', '順徳院', '百敷や古き軒端のしのぶにも', 'なほあまりある昔なりけり', 'ももしきやふるきのきばのしのぶにも', 'なほあまりあるむかしなりけり']うまく行きました!!
文字化けしまくった時はどうしようかと思いましたが、何とかなりましたね。
これで、ローカルcsvファイルを読み込んだものと全く同じものを読み込むことが出来ました。
うまく行ったのは良いですが、いまいち処理を理解していないのが気に食わないです。
さきのプログラムを分解してみました。説明(#)は省略しています。
import csv
from io import StringIO
import requests
url = "https://raw.githubusercontent~~~略~~~.csv"
response = requests.get(url)
response.encoding = response.apparent_encoding
a = response.text
b = StringIO(a)
reader = csv.reader(b)
#for row in reader:
#print(row)さて、それぞれ何が行われているのでしょうか?
まず「a = response.text」のところから、print(a)としてみました。
結果はこのようになります。
No,歌人,上の句,下の句,上の句(ひらがな),下の句(ひらがな)
1,天智天皇,秋の田のかりほの庵の苫をあらみ,わが衣手は露にぬれつつ,あきのたのかりほのいほのとまをあらみ,わがころもではつゆにぬれつつ
2,持統天皇,春過ぎて夏来にけらし白妙の,衣干すてふ天の香具山,はるすぎてなつきにけらししろたへの,ころもほすてふあまのかぐやま
~~~~~略~~~~~
98,従二位家隆,風そよぐ楢の小川の夕暮は,みそぎぞ夏のしるしなりける,かぜそよぐならのをがはのゆふぐれは,みそぎぞなつのしるしなりける
99,後鳥羽院,人もをし人もうらめしあじきなく,世を思ふゆゑにもの思ふ身は,ひともをしひともうらめしあぢきなく,よをおもふゆゑにものおもふみは
100,順徳院,百敷や古き軒端のしのぶにも,なほあまりある昔なりけり,ももしきやふるきのきばのしのぶにも,なほあまりあるむかしなりけりなるほど、単純な文字列として抽出してるわけですね。
では、「b = StringIO(a)」つまり「b = StringIO(response.text)」をprint(b)で出力してみます。
<_io.StringIO object at 0x000001E9ED2DEDC0>これは何でしょ?
静かなる名辞さんの【python】io.StringIOは便利なので使いこなそうでは、「ファイルオブジェクトのように見えるオブジェクト」と説明されています。
きちんと理解できてないですが、「b = StringIO(a)」は文字列からファイルっぽい何かに形式が変わったということだと思います。csv.readerは本来csv「ファイル」を開くものですので、この後がうまく処理できると推測できます。
では、次。「reader = csv.reader(b)」を出力してみます。print(reader)です。
<_csv.reader object at 0x000001E9ED3C1DC0>でた。よくわかりませんが、頭の部分が変化しています。
よし、受け入れよう!!とにかく、ファイル形式が変わってうまく処理できる。今はこれが限界です。
5.データ読み込み③ ~パンダにスクレイピングをさせにけり~
本来ならば、ここまでで終わるはずでしたが、途中でこんなもの【初心者向け】ColaboratoryでCSVを読み込む最も簡単な方法 ⇒ Pandas (+Github)を見つけてしまいました。
これはやってみるしかないでしょう!!
見よう見まねでやってみます。ちなみに使われているpandasというモジュールはAnacondaには入っているのでそのまま使っていますが、標準ではインストールされていません。
pandasはデータ分析とかに使われるライブラリだそうです。
import pandas as pd
csv = "https://raw.githubusercontent.com/nyoronjp/Ogura_Hyakunin_Isshu.csv/master/%E5%B0%8F%E5%80%89%E7%99%BE%E4%BA%BA%E4%B8%80%E9%A6%96.csv"
df = pd.read_csv(csv)
print(df)で、実行してみました。
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x89 in position 0: invalid start byteまたもや、utf-8が引っかかっています。
恐るべき「百人一首」・・解決法を調べてみました。
たぬハックさんのこちらのサイトを参考にさせていただきました。【Python】PandasでCSVファイルを読み込み/書き出しする実践テクニック集
pandasのいろいろなトラブル事例に対処法を書かれています。
これをふまえて、プログラムを修正しました。
import pandas as pd
csv = "https://raw.githubusercontent.com/nyoronjp/Ogura_Hyakunin_Isshu.csv/master/%E5%B0%8F%E5%80%89%E7%99%BE%E4%BA%BA%E4%B8%80%E9%A6%96.csv"
df = pd.read_csv(csv, encoding='shift-jis')
print(df)結果、このようになりました。
No 歌人 上の句 下の句 上の句(ひらがな) 下の句(ひらがな)
0 1 天智天皇 秋の田のかりほの庵の苫をあらみ わが衣手は露にぬれつつ あきのたのかりほのいほのとまをあらみ わがころもではつゆにぬれつつ
1 2 持統天皇 春過ぎて夏来にけらし白妙の 衣干すてふ天の香具山 はるすぎてなつきにけらししろたへの ころもほすてふあまのかぐやま
2 3 柿本人麻呂 あしびきの山鳥の尾のしだり尾の ながながし夜をひとりかも寝む あしびきのやまどりのをのしだりをの ながながしよをひとりかもねむ
3 4 山辺赤人 田子の浦にうち出でてみれば白妙の 富士の高嶺に雪は降りつつ たごのうらにうちいでてみればしろたへの ふじのたかねにゆきはふりつつ
4 5 猿丸大夫 奥山に紅葉踏み分け鳴く鹿の 声聞く時ぞ秋は悲しき おくやまにもみぢふみわけなくしかの こゑきくときぞあきはかなしき
.. ... ... ... ... ... ...
95 96 入道前太政大臣 花さそふ嵐の庭の雪ならで ふりゆくものはわが身なりけり はなさそふあらしのにはのゆきならで ふりゆくものはわがみなりけり
96 97 権中納言定家 来ぬ人を松帆の浦の夕なぎに 焼くや藻塩の身もこがれつつ こぬひとをまつほのうらのゆふなぎに やくやもしほのみもこがれつつ
97 98 従二位家隆 風そよぐ楢の小川の夕暮は みそぎぞ夏のしるしなりける かぜそよぐならのをがはのゆふぐれは みそぎぞなつのしるしなりける
98 99 後鳥羽院 人もをし人もうらめしあじきなく 世を思ふゆゑにもの思ふ身は ひともをしひともうらめしあぢきなく よをおもふゆゑにものおもふみは
99 100 順徳院 百敷や古き軒端のしのぶにも なほあまりある昔なりけり ももしきやふるきのきばのしのぶにも なほあまりあるむかしなりけり
[100 rows x 6 columns]ちなみに、anadcondaをインストールした際についてきたPython実行ソフト「jupyter Notebook」というソフト上ではこのよう出力されていました。
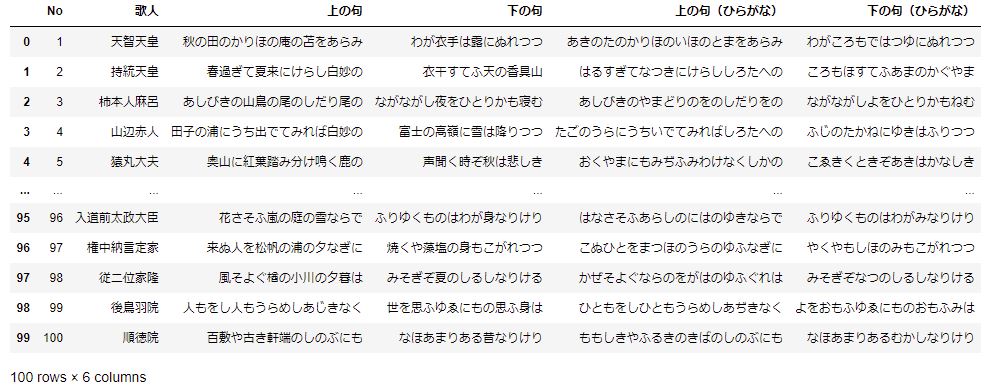
ヤバいですね。表になっています。
意図していませんでしたが、新たな扉を開いてしまったようです。
これ以上深追いすると、目的を見失いそうなので、ここまでにしましょう。
ということで、百人一首を作りたくてcsvファイルの読み込みをやっていたわけですが、思わぬゾーンまで突入してしまいました。
本来のゲームはあまり進んでいないですが、多くを学べたのでOKです!
長くなりすぎているので今回はここまで!!次回はゲームつくりに入る(はず)
To Be Continued : Pythonで百人一首クイズを作ろう ep 2
PyQさんで勉強中!



コメント