
APIって調べても良く分からない・・・
とにかく使ってみようぜ!
「API」をご存じでしょうか?
プログラミングをやっている方は、「当たり前!!」って方も多いと思います。
一方で、プログラミングに縁のない方や初学者は、まず聞いたことない言葉だと思います。
もちろん、私もほんの少し前まで聞いたことありませんでした。
私はWebスクレイピング(=Web上の情報を解析して収集、まとめるプログラム)の学習中に出てきて、なんとなく分かったけども、実態が分からないヤツでした。
ざっくりいうと、
APIとは、「Webサイトに問い合わせて、欲しい情報をGetできるしくみ、サービス」
という感じです。
まだピンと来てないので、とにかくやってみます。
(2021年4月30日:学習開始70日目 PyQさんで勉強中!)
さて、APIときいて思い出すのは、APC = A Perfect Circleです。
Toolってバンド(こっちも最高)のボーカルのかけもちバンドで、暗く、熱く、美しくというイメージです。
今回は、その中でも美しい成分多めの「So Long, And Thanks For All The Fish」を聞きながらやっていきます。
ちなみに、暗め成分多めなら、Beatlesの暗黒カバー「Imagine」も最高!
(どっちも曲名から公式YouTubeに飛びます。)
「So Long, And Thanks For All The Fish」はこっち
「Imagine」はこっち
では、「API」、やっていきましょう。
1.「API」とは何か?
「API」とは、「アプリケーション プログラミング インタフェース」だそうです。
はい、忘れましょう。
広義では、いろいろと意味を持つようですが、ここでは、
「プログラム上で問い合わせると、答えが返ってくるサービス」
程度の理解で良いと思います。
この「サービス」の部分ですが、Google、Amazon、楽天をはじめ、大手のサイトから個人サイトまでいろいろなサイトが「API」を発行しており、有償や無償で使えるという意味です。
この「外部サイトの発行しているシステムを使う。」というのがポイントの一つです。
では、「WEBページスクレイピング」と「WEB APIの利用」は何が違うのでしょうか?
(WEB APIもWEBページのスクレイピングの1種かもしれませんが・・・流しましょう。)
WEBページのスクレイピングは、公開されたWEBページの情報を解析して、データを収集します。
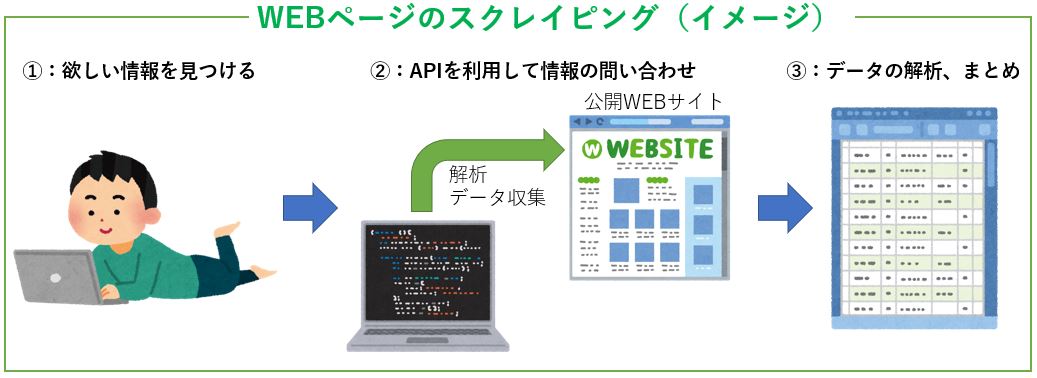
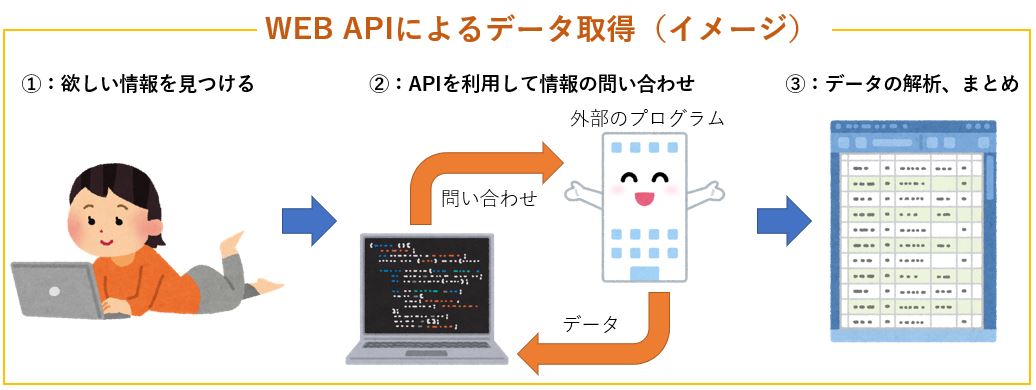
一方で、WEB APIの利用では、WEBページそのものを解析せずに、外部に問い合わせをしてデータを返してもらいます。
スクレイピングは違法行為ではありませんが、「勝手に」WEBページを解析して情報を収集します。
大量にアクセスをすると、そのサイトのサーバーに負荷をかけてしまいます。
そのため、WEBサイトによっては利用規約で禁じているページもすくなくありません。
(例えば、Amazon、Twitterをはじめ多くのサイトで禁じています。)
【※絶対に自動化してはいけない】自動化禁止サイトまとめ!
一方、APIは、基本的にデータを持っている会社や個人が発行しているものです。
APIの利用規約や制限はありますが、「使っていいよ!」というサービスです。
スクレイピングを禁止しているAmazonやTwitterですが、それぞれAPIは発行しています。
(ただし、どうやら勝手にほかのページのデータを取りに行く「野良API」もあるようです。注意が必要です。)
上の説明は、かーなり雑なものです。
実際は、APIを使って認証できたり(GoogleじゃないサイトなのにGoogleアカウントで入れるヤツ)、もっといろいろできるようです。
世の中に無数にあるAPIのうち、今回は「Google Books API」を使ってみます。
2.やりたいこと
Pythonの最新本を調べるには、どうすれば良いでしょうか?
私なら、
①:Amazonにアクセスする
②:「Python」で検索
③:「出版年月が新しい順番」に並び替える
というふうにします。べたですね。
実際にやってみるとどうなるでしょうか?
見事に洋書が並びます。そう、「Python」の本は圧倒的に洋書が多いのです。
これを日本語の本だけを抽出して、新しい順に並べるのは多分やり方はあるのでしょうが、地味~にやり方が分かりません。
そこで
「APIを使って日本語のPython本の新刊情報を取得する」
という事をやってみたいと思います。
今回はAmazonも楽天もAPIはありますが、今回は「Google Books API」を使用してみます。
Google Books APIs公式ページ
公式にも記載がありますが、検索だけな認証キーなしで使えます。
また、こちらのページGoogle Books APIの使い方~その4~も参考にさせていただきました。
では、早速やってみましょう。(今回は1冊検索のみです。新刊情報取得は次回!)
3.下準備(RequestsとPandasのインポート)
進める前に、下準備を行います。
今回は、標準外のライブラリとして、RequestライブラリとPandasiライブラリを使います。
インポートの仕方は、過去記事Pandasでグラフに針を落とす ~ビュフォンの針を落とす ep4~参照。
まあ、簡単なので、手順は以下です。(Windowsの場合)
①:コマンドプロンプトを開く
②:以下のコマンドをそれぞれ入力して実行
C:\Users\XXXXX>pip install requestsC:\Users\XXXXX>pip install pandas
終わりです。
Pandasは別に必須ではありませんが、最後にデータをまとめるときに使おうと思います。
4.APIを使ってみよう ~1件検索してみる~
まずは欲張らずに1件のみ検索してみようと思います。
「Python2年生 スクレイピングのしくみ」を検索してみようと思います。
本書は、今回の検証をするのに大いに参考にしています。(なおGoogle Books APIはやってません)
さて、まずはやってみましょう。
Google Books APIs公式ページをよく読んでいく必要があります。全編英語!頑張りましょう。
だーっと読んでいくと、
「https://www.googleapis.com/books/v1/volumes?q=search+terms」
と検索の例があります。
ここの「q」のところに検索の内容を入れればよいようです。
今回は、ISBN、書籍に割り当てられた識別番号を使用して検索をかけてみます。
手元に本書があるので、ISBNはすぐに分かります。9784798161914です。
公知情報なので、調べればすぐに出てきます。
公式ページを読んでいくと、ISBNで検索する場合は、
「q=isbn:(番号)」と入れればよいようです。
早速やってみましょう。
RequestsライブラリでURLにアクセスして情報を取得します。
import requests
url = 'https://www.googleapis.com/books/v1/volumes?q=isbn:9784798161914' #GooglBooksAPI
response = requests.get(url) #情報の取得
print(response)結果はこのように出力されます。
<Response [200]>ダメな感じしますね。
調べると、形式の問題のようです。
Google Books APIに限らず、多くのAPIではJSONという形式でデータが返ってくるようです。
これはJavaScript のデータ形式だそうで、そのまま扱えません。
修正しましょう。
JSON形式のデータをPythonで読めるように変化する必要があります。
Pythonにはその名も「JSON」というライブラリがあり、これで解決できます。
たった5行!!
import requests
import json
url = 'https://www.googleapis.com/books/v1/volumes?q=isbn:9784798161914' #GooglBooksAPI
response = requests.get(url).json() #情報の取得,json変換
print(response)出力結果はこうなります。
(実際は、入力したURLをブラウザで開いたものです。あとIDとかetagってのは消しました、なんとなく。)
"kind": "books#volumes",
"totalItems": 1,
"items": [
{
"kind": "books#volume",
"id": "7EmwDwAAQBAJ",
"etag": "+DHf0yjkSyI",
"selfLink": "https://www.googleapis.com/books/v1/volumes/XXXXXXXXX",
"volumeInfo": {
"title": "Python2年生 スクレイピングのしくみ 体験してわかる!会話でまなべる!",
"authors": [
"森巧尚"
],
"publisher": "翔泳社",
"publishedDate": "2019-10-04",
"description": "Pythonでスクレイピングを体験してみよう! ~~~~~略~~~~~
{
"type": "ISBN_13",
"identifier": "9784798161914"
},
{
"type": "ISBN_10",
"identifier": "4798161918"
}
],
"readingModes": {
"text": false,
"image": true
},
"pageCount": 192,
"printType": "BOOK",
"maturityRating": "NOT_MATURE",
"allowAnonLogging": false,
"contentVersion": "0.13.0.0.preview.1",
"panelizationSummary": {
"containsEpubBubbles": false,
"containsImageBubbles": false
},
"imageLinks": {
"smallThumbnail": "http://books.google.com/books~~~~~略~~~~~"
"thumbnail": "http://books.google.com/books/~~~~~略~~~~~"
},
"language": "ja",
"previewLink": "http://books.google.co.jp/~~~~~略~~~~~",
"infoLink": "http://books.google.co.jp/~~~~~略~~~~~",
"canonicalVolumeLink": "https://books.google.com/books/about/~~~~~略~~~~~"
},
"saleInfo": {
"country": "JP",
"saleability": "NOT_FOR_SALE",
"isEbook": false
},
"accessInfo": {
"country": "JP",
"viewability": "PARTIAL",
"embeddable": true,
"publicDomain": false,
"textToSpeechPermission": "ALLOWED",
"epub": {
"isAvailable": false
},
"pdf": {
"isAvailable": false
},
"webReaderLink": "http://play.google.com/books/~~~~~略~~~~~,
"accessViewStatus": "SAMPLE",
"quoteSharingAllowed": false
},
"searchInfo": {
"textSnippet": "Pythonでスクレイピングを体験してみよう! 【スクレイピングとは】 ~~~~~略~~~~~"
}
}
]
}1件でも非常に長いデータが返ってきました。
データを見ると、「Python2年生 スクレイピングのしくみ」が返ってきていることが分かります。
まずは成功です!!!
今回、APIにISBNのデータを入力することで、結果が返ってきています。
既存のWEBページをスクレイピングしているわけではないというのが、今回のポイントの一つです。
さて、もう少しデータを詳しく見てみましょう。
まず分かるのは「辞書型データである」という事です。全体が{}で囲まれていますね。
という事は個別のデータを抽出するには、辞書型データとしてデータを取り出せば良さそうです。
データ件数は、「’totalItems’: 1」と表現されています。
さらに基本情報は
「{‘itemes’:[{‘kind’:~~~~, ‘volumeInfo’:{’title’:~~~}」という形で
「辞書型データ」の中の「リスト型データ」の中の「辞書型データ」の中の「辞書型データ」という4つの入れ子にデータがあるという構造を取っていることが分かります。
ややこしいですね~。しかし一つずつ紐解けば大丈夫そうです。
まずは、件数とタイトルを取り出してみましょう。
import requests
import json
url = 'https://www.googleapis.com/books/v1/volumes?q=isbn:9784798161914' #GooglBooksAPI
response = requests.get(url).json() #情報の取得,json変換
totalitems = response['totalItems'] #件数
items_list = response['items'] #items リストデータ
items = items_list[0] #items
info = items['volumeInfo']
title = info['title']
print('件数:', totalitems)
print('タイトル:', title)出力はこうです。
件数: 1
タイトル: Python2年生 スクレイピングのしくみ 体験してわかる!会話でまなべる!できましたね!!!
では、最終的にアウトプットしたいモノを全部出力してみましょう。
最終的にアウトプットしたいのは、欲張って、
①:タイトル(済)
②:著者
③:出版社
④:出版日
⑤:ページ数
⑥:書籍種別
⑦:言語
⑧:要約、説明
とします。
import requests
~~~~~略~~~~~~
items = items_list[0] #items
info = items['volumeInfo']
title = info['title']
author = info['authors']
publisher = info['publisher']
publisheddate = info['publishedDate']
pages = info['pageCount']
printtype = info['printType']
description = info['description'] #要約
language = info['language']
print('件数:', totalitems)
print('タイトル:', title)
print('著者:', author)
print('出版社:', publisher)
print('出版日:', publisheddate)
print('ページ数:', pages)
print('種別:', printtype)
print('言語:', language)
print('要約:', description)出力結果です。
件数: 1
タイトル: Python2年生 スクレイピングのしくみ 体験してわかる!会話でまなべる!
著者: ['森巧尚']
出版社: 翔泳社
出版日: 2019-10-04
ページ数: 192
種別: BOOK
言語: ja
約: Pythonでスクレイピングを体験してみよう! 【スクレイピングとは】~~~~略~~~~~
うまくできましたね。準備はここまでです。
しかし、今回はここまでとします。
次回、PythonでPythonの最新本を探していきましょう。
To Be Continued :Google Books APIを使ってみる ep2
PyQさんで勉強中!



コメント