Spotify APIを使って楽曲分析をしてみた。
コロナ禍は音楽にどのような影響を与えたのだろうか?
記事①:PythonでSpotify APIを使ってみる ~全ての音楽愛好家のためのSpotify API ep 1~
記事②:曲のテンポ、コードを取得する ~全ての音楽愛好家のためのSpotify API ep 2~
前回、Spotify API で楽曲からいろいろなデータを取得できる事が分かりました。
このデータを用いて分析をしてみましょう。
年ごとのヒット曲から分析を行って、コロナ禍が音楽に与えた影響を調べてみます。
音楽の楽しみ方は人それぞれ。「データで楽しむ音楽」もあっていいでしょう!
もしかしたら、楽曲制作をしている方は、楽曲分析の観点からヒットする曲を狙いに行くことができるかもしれません。
(2021年5月29日:学習開始99日目 PyQさんで勉強中!)
年ごとのヒットチャートを調査していきます。
ところで2020年、最大のヒット曲って何でしょうか?
いろいろな意見はありますが、個人的にはTONES AND Iの「DANCE MONKEY」です!
独特の声と跳ねるようなリズム感。ちょっと近年の他の曲にはなかった感性の曲です。
(曲名から公式YouTubeに飛びます。)
では、やっていきましょう。
最終のプログラムはGitHubに置いておきます。
1.コロナ禍が音楽に与えた影響(結論)
今回、かなり長くなってしまったので、結論から書きます。
分析の概要は、Spotifyが作成している2017年~2020年のヒット曲プレイリストの楽曲について、楽曲データを分析しています。
2017年~2019年はコロナ禍の影響を受ける前、2020年はコロナ禍の影響を受けた後と仮定してデータを見ていきます。
記載のグラフは、ヒストグラムで書かれています。
プレイリストの曲のパラメーターを10段階に区切って(一部は2、12段階)、比較しています。
パラメーターの内容は、Spotify独自の指標でAPIから取得できます。前回記事参照。
では見ていきましょう。
まずは、「danceability=踊りやすさ」です。
これは、高いほど踊れる楽曲という事です。
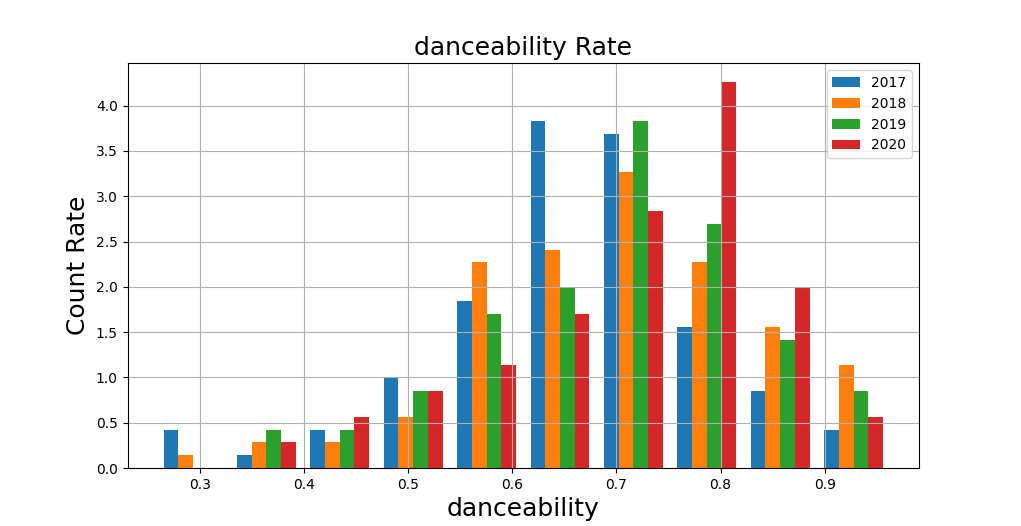
明らかに2020年の曲はdanceabilityの値が高くなる傾向があります。
次に、「liveness=ライブっぽさ」を見ていきましょう。
高いほどライブ感が強い曲という指標です。
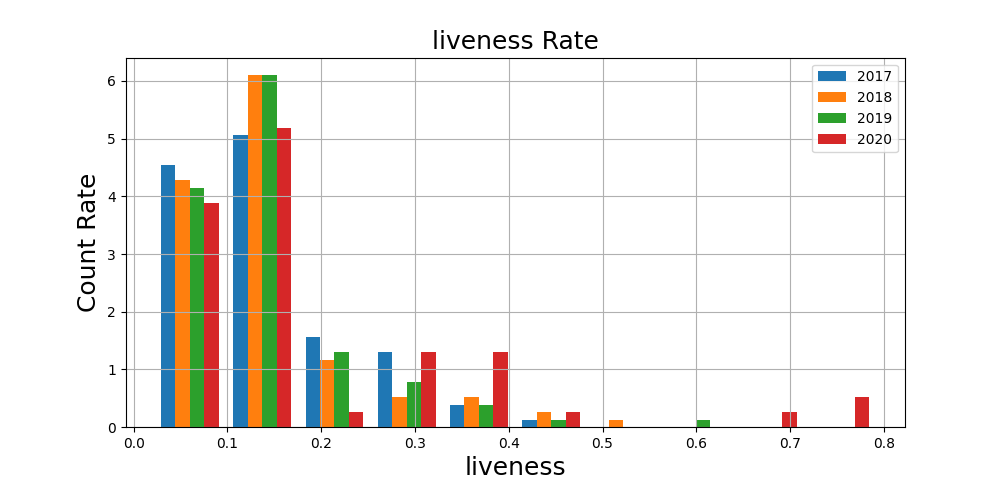
ライブっぽさも2020年は高くなる傾向が見られます。
次は、「valence=ポジティブさ」を見てみます。
高いほどポジティブ感(幸福感、陶酔感)が強く、低いほどネガティブ感(悲壮感、怒り)が強いとされています。。
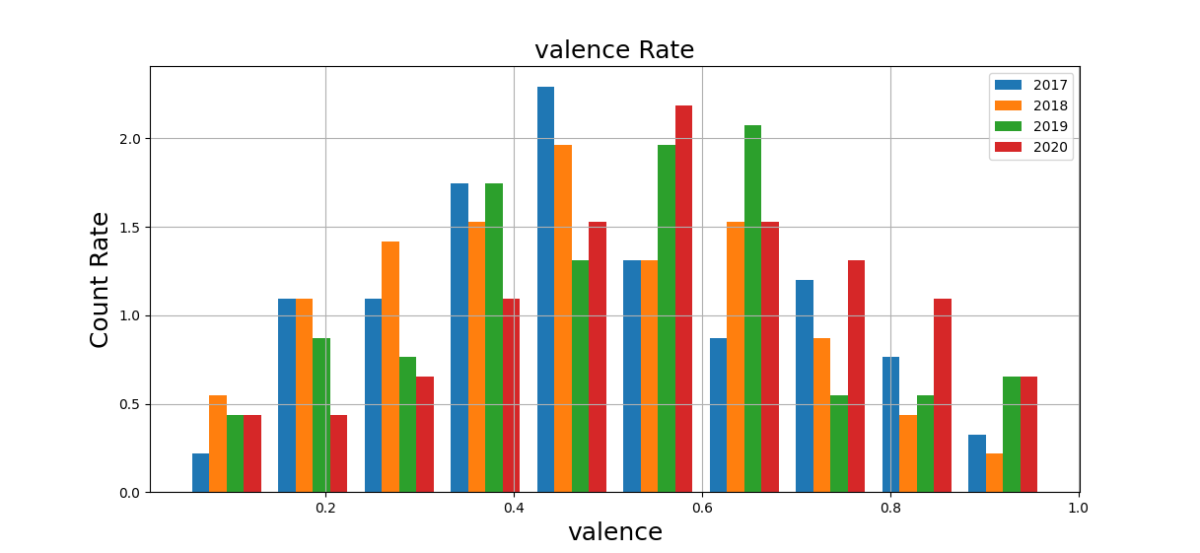
valenceも2020年は高い傾向が見られます。
2020年の曲はポジティブ感が強めという事です。
ここまでの結果をまとめてみましょう。
2020年の曲は、2017年~2019年の曲と比較して
「踊れて」「ライブ感が強く」、「ポジティブ感が強い」曲がヒットしています。
コロナ禍で外出や実際のライブが制限される中、逆に曲の中だけでも踊ったり、ライブを感じたりしたいという思いがあるのかもしれません。
そういえば、日本でも星野源さんが「うちで踊ろう」という曲を配信して話題になりましたね。
次は、楽曲そのものの性質を見てみましょう。
tempo、key、modeの比較を見てみましょう。
ちなみにkeyは0~11なので12分割、modeは0か1なので2分割で表現しています。
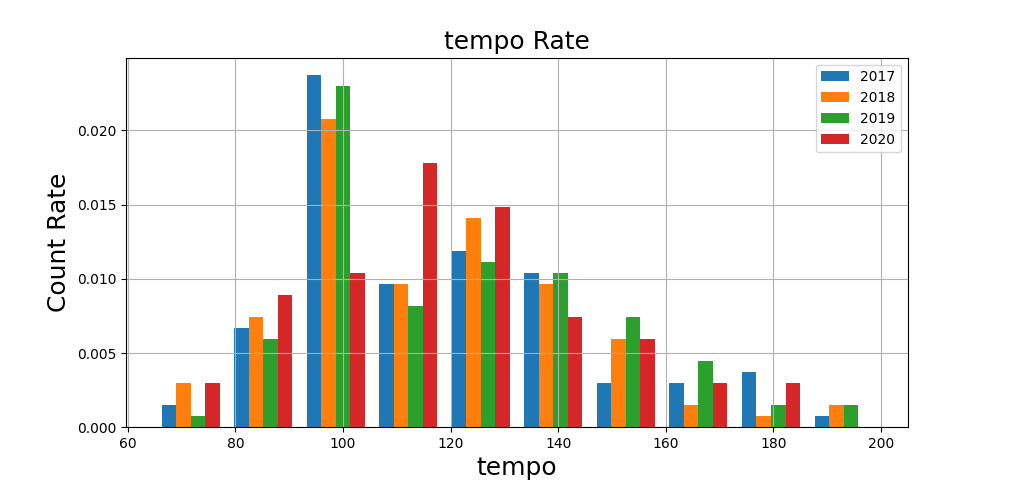
2020年の曲はtempoが高い=速き曲になる傾向が見られます。
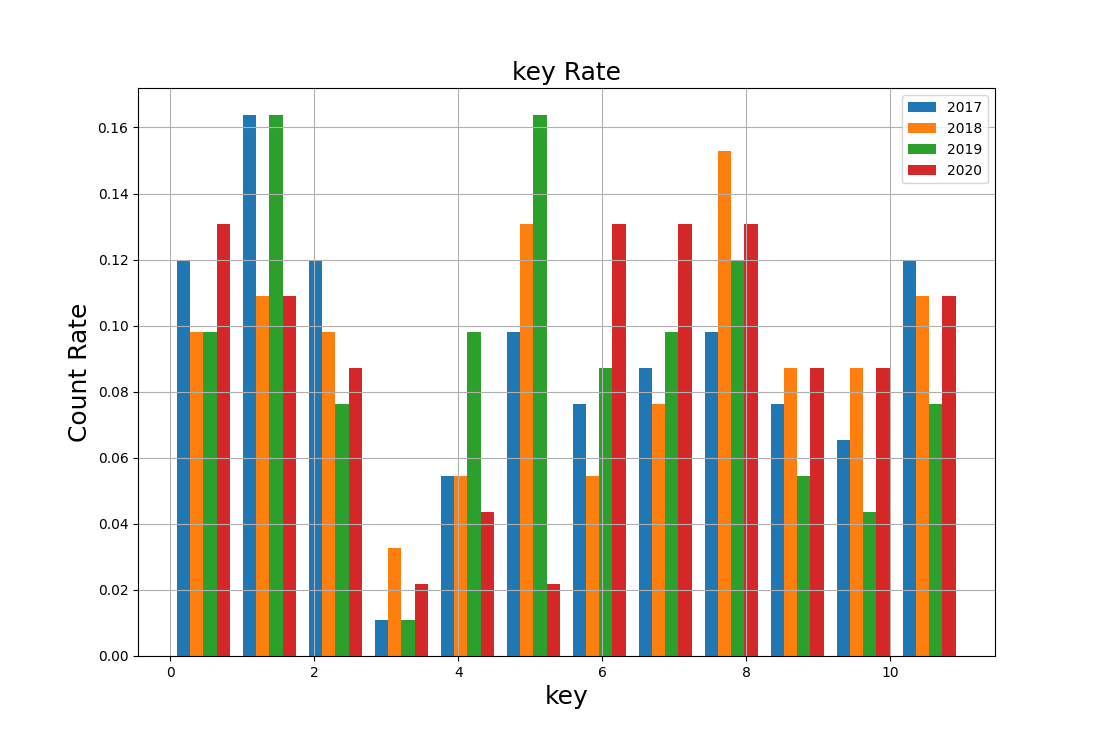
keyはピッチクラスで表現されています。
2020年のヒット曲はKey=4(E)、Key=5(F)が少なく、Key=6(F♯)、Key=7(G)が多い傾向があります。
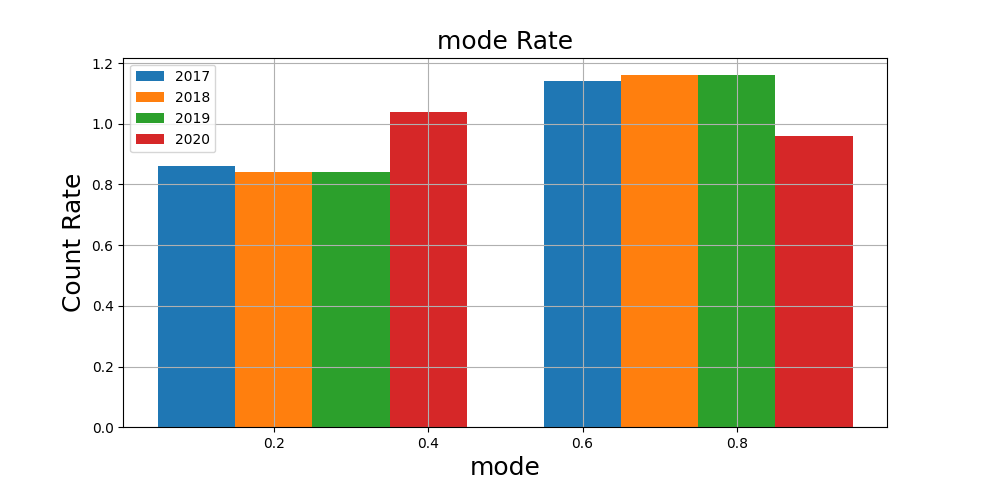
若干の差ですが、2020年の曲はmode=0(マイナー)が多く、mode=1(メジャー)の曲が多い傾向があります。
楽曲面の結果をまとめてみましょう。
2020年の曲は、2017年~2019年の曲と比較して、
「テンポが速くて」「キーがF#が多く」、「マイナー調が若干多い」
という事が分かります。
テンポが速いというのは、「踊れて」「ライブ感が強く」、「ポジティブ感が強い」という結果と類似しているように思われます。
一方で差がでるのが予想外だったのが、2020年の曲は
「キーはF#、Gが多く、E、Fが少ない」
という結果です。
知らべてみると、キーにはそれぞれ印象があるようです。
Gは「雄大さ」や「元気さ」という印象に対し、EやFは「軽快さ」や「優しさ」という印象だそうです。
このあたりも実は世相を反映しているようにもみえます。
(以下のサイトを参考にさせていただきました。
キー(調)の特徴・イメージを一覧にしてまとめてみた!~メジャー:長調編~【色彩・印象・性格】
調(キー)の特徴・イメージを一覧にしてまとめてみた!!~マイナー:短調編~【色彩・印象・性格】
様々なキーの特徴まとめ&調の選択について)
今回、2020年の楽曲は2017年~2019年までの傾向から少しズレた傾向を示す事が分かりました。
全てがコロナの影響とはいえないですが、大きな要因の一つであると推測されます。
楽曲制作をしている方は、現在好まれている曲を知ることでヒット曲を作ることが出来るかもしれません。
では、分析にいたるまでの方法を振り返っていきます。
2.Spotify APIを使おう
Spotify APIはSpotifyの所有しているバックデータを取得したり、Spotifyを操作したりできるAPIです。公式のWeb API Tutorial
Spotify APIを使うには、Spotifyの登録
が必要です。
また、spotipyというライブラリを使っていくので、このインストールも必要です。
そのあたりは、PythonでSpotify APIを使ってみる ~全ての音楽愛好家のためのSpotify API ep 1~に記載しているので、ご参照ください。
準備編はこれで終了です。
3.楽曲分析の方針
分析の方針を考えましょう。
冒頭に書いたように、 年ごとの曲を収集して分析を行います。
具体的には、以下の流れで分析していきます。
・分析手順
①:Spotifyのヒット曲プレイリスト(例:「Top Hits of 2019」)からトラックリストを抽出
↓
②:トラックリストからトラック(曲)のURLを抽出
↓
③:トラックの楽曲パラメータを抽出
↓
④:CSVファイルにまとめて分析
③の「トラックの楽曲パラメータを抽出」は前回つくったプログラムを流用できそうです。
では、順にやっていきましょう。
4.楽曲分析取得プログラムをつくろう
今回の本編です。
では、早速やってみましょう。
例に挙げているSpotify作成のプレイリスト「Top Hits of 2019」でやってみましょう。
プレイリストのURL取得方法はPythonでSpotify APIを使ってみる ~全ての音楽愛好家のためのSpotify API ep 1~参照。
まずは、
手順①:Spotifyのヒット曲プレイリスト(例:「Top Hits of 2019」)からトラックリストを抽出
から始めます。
前回までを参考に、プレイリストのURLからデータの取得と、APIの認証までです。
spotipyライブラリの中から、playlist_tracksモジュールを使用しています。
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
#入力パート
playlist_url = 'https://open.spotify.com/playlist/37i9dQZF1DWVRSukIED0e9'
#認証パート
my_id ='0000000000000000000000' #client ID
my_secret = '0000000000000000000000' #client secret
ccm = SpotifyClientCredentials(client_id = my_id, client_secret = my_secret)
spotify = spotipy.Spotify(client_credentials_manager = ccm)
list_data = spotify.playlist_tracks(playlist_url)
print(list_data)結果は省略しますが、膨大なデータが出てきました。
どうやら辞書型のデータです。
{辞書}.keys()
で、辞書型データのKeyを取得してみましょう。
プログラムはこんな感じです。
~~~~~略~~~~~
list_data = spotify.playlist_tracks(playlist_url)
print(list_data.keys())結果は以下のように出力されます。
dict_keys(['href', 'items', 'limit', 'next', 'offset', 'previous', 'total'])いろいろとKeyがあることが分かります。
省略しますが出力して調べていくと、「items」が楽曲データ、「total」がプレイリストの数であることが分かりました。
まずは、「total」の方を出力してみましょう。
~~~~~略~~~~~
list_data = spotify.playlist_tracks(playlist_url)
track_num = list_data['total'] #play_list_count
print(track_num)結果はこのようになります。
100100です。
「Top Hits of 2019」プレイリストの楽曲数も100なので正しそうです。
次にこのデータから、
手順②:トラックリストからトラック(曲)のURLを抽出
に進みましょう。
次に、楽曲データを取得してみます。
~~~~~略~~~~~
list_data = spotify.playlist_tracks(playlist_url)
track_num = list_data['total']
print(list_data['items'])結果は省略しますが、膨大なデータが返ってきます。
末尾だけ見てみましょう。
~~~~~略~~~~~'video_thumbnail': {'url': None}}]末尾から分かるのは、リスト型のデータであるという事です。
という事でリストの数を数えてみましょう。
「len(リスト)」
でリストの要素をカウントできます。
~~~~~略~~~~~
list_data = spotify.playlist_tracks(playlist_url)
track_num = list_data['total']
print(len(list_data['items']))結果はこうなります。
100100トラックに100個のリスト。
「トラックごとにリスト型のデータでまとめられている」
と考えられます。
では例として先頭のリスト(0番目のリスト)を見てみましょう。
~~~~~略~~~~~
list_data = spotify.playlist_tracks(playlist_url)
track_num = list_data['total']
print(list_data['items'][0])またもや膨大な結果が返ってきます。
ここも末端だけ見てみましょう。
~~~~~略~~~~~ 'video_thumbnail': {'url': None}}ここからわかるのは、「辞書型のデータである」という事。
では、辞書型データのKeyを取得してみましょう。
~~~~~略~~~~~
list_data = spotify.playlist_tracks(playlist_url)
track_num = list_data['total']
print(list_data['items'][0].keys())このように出力されました。
dict_keys(['added_at', 'added_by', 'is_local', 'primary_color', 'track', 'video_thumbnail'])みるからに「track」が楽曲のデータっぽいですね。
出力してみましょう。
~~~~~略~~~~~
list_data = spotify.playlist_tracks(playlist_url)
track_num = list_data['total']
print(list_data['items'][0]['track']省略しますが、辞書型のデータが返ってきます。
さらにkey()を使って分析して解析をしました。(略)
いろいろなデータがありますがここで取得したいのは、「トラックのURL」です。
プログラムを書いてみます。
~~~~~略~~~~~
list_data = spotify.playlist_tracks(playlist_url)
track_num = list_data['total']
print(list_data['items'][0]['track']['external_urls']結果はこのようになります。
{'spotify': 'https://open.spotify.com/track/2YpeDb67231RjR0MgVLzsG'}データが取得できました。
keyが’spotify’の辞書型データになっています。
では、このようにすればURL単体で取得できそうです。
~~~~~略~~~~~
list_data = spotify.playlist_tracks(playlist_url)
track_num = list_data['total']
print(list_data['items'][0]['track']['external_urls']['spotify'])結果はこうなりました。
https://open.spotify.com/track/2YpeDb67231RjR0MgVLzsGトラックのURLが取得できました。
今のところ、0番目のトラックのURLを取得した段階です。
では、プレイリストの全てのトラックのURLを取得して、リストにまとめてみましょう。
~~~~~略~~~~~
list_data = spotify.playlist_tracks(playlist_url)
track_num = list_data['total']
urls_list =[]
for i in range(track_num):
track_url = list_data['items'][i]['track']['external_urls']['spotify']
urls_list.append(track_url)
print(urls_list)結果は省略しますが、URLのリストが取得できています。
次に、
手順③:トラックの楽曲パラメータを抽出
に進みましょう。
前回の記事を参考に曲のデータを取得してみます。ほぼコピペです。
まずは0番目のトラックのデータのみを取得してみます。
また、APIにアクセスする間隔は1秒間隔をあけるようにします。(time.sleep(1))
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
import time
~~~~~略~~~~~
list_data = spotify.playlist_tracks(playlist_url)
track_num = list_data['total']
urls_list =[]
for i in range(track_num):
track_url = list_data['items'][i]['track']['external_urls']['spotify']
urls_list.append(track_url)
time.sleep(1) #1sec stop
results = spotify.audio_features(urls_list[0])
result = results[0]
for key, val in result.items():
print(f'{key} : {val}')結果はこのようになります。
danceability : 0.878
energy : 0.619
key : 6
loudness : -5.56
mode : 1
speechiness : 0.102
acousticness : 0.0533
instrumentalness : 0
liveness : 0.113
valence : 0.639
tempo : 136.041
type : audio_features細かいパラメーターの説明も前回に譲ります。
現段階ではプレイリストの1曲目のデータを取得したにすぎません。
今回はプレイリストの曲のデータを表の形でまとめたいと思います。
「表といえばPandas」です。
(PandashはインストールはPandasでグラフに針を落とす ~ビュフォンの針を落とす ep4~参照)
前々回の記事でも似たような操作をしたので簡単ですね。
ここでデータにまとめたいのは、上のデータに加えて、
『曲名』『アーティスト名』『URL』
をまとめたいと思います。
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
import time
import pandas as pd
~~~~~略~~~~~
list_data = spotify.playlist_tracks(playlist_url)
track_num = list_data['total']
urls_list =[]
for i in range(track_num):
track_url = list_data['items'][i]['track']['external_urls']['spotify']
urls_list.append(track_url)
time.sleep(1) #1sec stop
track_df = pd.DataFrame(index=[],
columns=['Track', 'Artist', 'danceability', 'energy',
'key', 'loudness', 'mode', 'speechiness', 'acousticness',
'instrumentalness', 'liveness', 'valence','tempo', 'type', 'URL'])
track_data = spotify.track(urls_list[0])
time.sleep(1) #1sec stop
track_feature = spotify.audio_features(urls_list[0])[0]
track_df = track_df.append({
'Track' : track_data['name'],
'Artist' : track_data['album']['artists'][0]['name'],
'danceability' : track_feature['danceability'],
'energy' : track_feature['energy'],
'key' : track_feature['key'],
'loudness' : track_feature['loudness'],
'mode' : track_feature['mode'],
'speechiness' : track_feature['speechiness'],
'acousticness' : track_feature['acousticness'],
'instrumentalness' : track_feature['instrumentalness'],
'liveness' : track_feature['liveness'],
'valence' : track_feature['valence'],
'tempo' : track_feature['tempo'],
'type' : track_feature['type'],
'URL' : urls_list[0]}, ignore_index=True)
print(track_df)結果はこのようなります。
Track Artist danceability energy key loudness mode speechiness acousticness instrumentalness liveness valence tempo type URL
0 Old Town Road - Remix Lil Nas X 0.878 0.619 6 -5.56 1 0.102 0.0533 0 0.113 0.639 136.041 audio_features https://open.spotify.com/track/2YpeDb67231RjR0...まずは1トラックのデータが取得できました。
では、For文をつかって、全てのデータを取得しましょう。
繰り返し回数=トラックURLの数です。
~~~~~略~~~~~
time.sleep(1) #1sec stop
track_df = pd.DataFrame(index=[],
columns=['Track', 'Artist', 'danceability', 'energy',
'key', 'loudness', 'mode', 'speechiness', 'acousticness',
'instrumentalness', 'liveness', 'valence','tempo', 'type', 'URL'])
for i in range(len(urls_list)):
track_data = spotify.track(urls_list[i])
time.sleep(1) #1sec stop
track_feature = spotify.audio_features(urls_list[i])[0]
track_df = track_df.append({
'Track' : track_data['name'],
'Artist' : track_data['album']['artists'][0]['name'],
'danceability' : track_feature['danceability'],
'energy' : track_feature['energy'],
'key' : track_feature['key'],
'loudness' : track_feature['loudness'],
'mode' : track_feature['mode'],
'speechiness' : track_feature['speechiness'],
'acousticness' : track_feature['acousticness'],
'instrumentalness' : track_feature['instrumentalness'],
'liveness' : track_feature['liveness'],
'valence' : track_feature['valence'],
'tempo' : track_feature['tempo'],
'type' : track_feature['type'],
'URL' : urls_list[i]}, ignore_index=True)
print(track_df)結果はこのようになります。
1トラックあたり1秒停止が挟まっているので、100トラックなら100秒、つまり1分40秒かかります。
Track Artist danceability energy key loudness mode speechiness acousticness instrumentalness liveness valence tempo type URL
0 Old Town Road - Remix Lil Nas X 0.878 0.619 6 -5.560 1 0.1020 0.0533 0 0.1130 0.639 136.041 audio_features https://open.spotify.com/track/2YpeDb67231RjR0...
1 bad guy Billie Eilish 0.701 0.425 7 -10.965 1 0.3750 0.3280 0.13 0.1000 0.562 135.128 audio_features https://open.spotify.com/track/2Fxmhks0bxGSBdJ...
2 Señorita Shawn Mendes 0.759 0.548 9 -6.049 0 0.0290 0.0392 0 0.0828 0.749 116.967 audio_features https://open.spotify.com/track/6v3KW9xbzN5yKLt...
3 7 rings Ariana Grande 0.778 0.317 1 -10.732 0 0.3340 0.5920 0 0.0881 0.327 140.048 audio_features https://open.spotify.com/track/6ocbgoVGwYJhOv1...
4 Sunflower - Spider-Man: Into the Spider-Verse Post Malone 0.755 0.522 2 -4.368 1 0.0575 0.5330 0 0.0685 0.925 89.960 audio_features https://open.spotify.com/track/0RiRZpuVRbi7oqR...
.. ... ... ... ... .. ... ... ... ... ... ... ... ... ... ...
95 Swervin (feat. 6ix9ine) A Boogie Wit da Hoodie 0.581 0.662 9 -5.239 1 0.3030 0.0153 0 0.1110 0.434 93.023 audio_features https://open.spotify.com/track/1wJRveJZLSb1rjh...
96 Light On Maggie Rogers 0.657 0.569 2 -6.287 1 0.0542 0.2010 0.000014 0.1260 0.399 102.054 audio_features https://open.spotify.com/track/6UnCGAEmrbGIOSm...
97 Ladbroke Grove AJ Tracey 0.903 0.839 11 -9.447 0 0.2080 0.0939 0 0.1020 0.727 133.986 audio_features https://open.spotify.com/track/7b4ky1LlQLFhXHm...
98 rockstar (feat. 21 Savage) Post Malone 0.585 0.520 5 -6.136 0 0.0712 0.1240 0.00007 0.1310 0.129 159.801 audio_features https://open.spotify.com/track/0e7ipj03S05BNil...
99 Giant (with Rag'n'Bone Man) Calvin Harris 0.807 0.887 1 -4.311 0 0.0361 0.0160 0.000503 0.0811 0.606 122.015 audio_features https://open.spotify.com/track/5itOtNx0WxtJmi1...
[100 rows x 15 columns]全てのデータを取得できましたね。
次は、
手順④:CSVファイルにまとめて分析
に進みます。
取得したデータをCSVに出力してみましょう。
意外と時間がかかるので、CSVファイルに出力できたら、「Finish」と表示されるようにしました。
一旦の区切りになるので、全プログラムを表示しています。
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
import time
import pandas as pd
import csv
#入力パート
track_url = 'https://open.spotify.com/playlist/37i9dQZF1DWVRSukIED0e9'
#認証パート
my_id ='0000000000000000000000' #client ID
my_secret = '0000000000000000000000' #client secret
ccm = SpotifyClientCredentials(client_id = my_id, client_secret = my_secret)
spotify = spotipy.Spotify(client_credentials_manager = ccm)
list_data = spotify.playlist_tracks(playlist_url)
track_num = list_data['total']
if track_num > 100:
track_num =100
urls_list =[]
for i in range(track_num):
track_url = list_data['items'][i]['track']['external_urls']['spotify']
urls_list.append(track_url)
time.sleep(1) #1sec stop
track_df = pd.DataFrame(index=[],
columns=['Track', 'Artist', 'danceability', 'energy',
'key', 'loudness', 'mode', 'speechiness', 'acousticness',
'instrumentalness', 'liveness', 'valence','tempo', 'type', 'URL'])
for i in range(len(urls_list)):
track_data = spotify.track(urls_list[i])
time.sleep(1) #1sec stop
track_feature = spotify.audio_features(urls_list[i])[0]
track_df = track_df.append({
'Track' : track_data['name'],
'Artist' : track_data['album']['artists'][0]['name'],
'danceability' : track_feature['danceability'],
'energy' : track_feature['energy'],
'key' : track_feature['key'],
'loudness' : track_feature['loudness'],
'mode' : track_feature['mode'],
'speechiness' : track_feature['speechiness'],
'acousticness' : track_feature['acousticness'],
'instrumentalness' : track_feature['instrumentalness'],
'liveness' : track_feature['liveness'],
'valence' : track_feature['valence'],
'tempo' : track_feature['tempo'],
'type' : track_feature['type'],
'URL' : urls_list[i]}, ignore_index=True)
track_df.to_csv(output_filename, encoding='utf-8') #csvファイル出力
with open(output_filename, 'a', newline='') as f:
writer = csv.writer(f)
print('finish')CSVファイルが出来ていますね。
ファイルを開いてみましょう。

データがCSVファイルにまとめられています!
微妙に楽曲名が文字化けしてますが、解析には影響しないんで良しとしましょう。
では、次はまとめられたデータを解析してみましょう。
5.楽曲データ解析プログラムをつくろう
Spotify APIから離れて、取得したCSVファイルの解析に移ります。
事前に、先に作成したプログラムを使って、2017年、2018年、2019年、2020年のデータを取得して、CSVファイルにまとめています。
ここで、一つポイントがあります。
プレイリストのトラック数の違いです。2020年のデータのみトラック数が50になっています。
そのため、単純なデータ点数ではなく割合で分析することが必要です。
データを描写するのには、「matplotlib」という外部ライブラリを使用します。
では、プログラムを書いていきます。
ここでは、過程を省略して結果のみ記載します。
いくつかポイントがあります。
ポイント①:CSVファイルのパス(保存場所)は人により異なる
ポイント②:ヒストグラムで分析
ポイント③:ヒストグラムを正規化して表示(density=True)
ポイント④:plot_dataを変えて分析対象を変える。(例では「danceability」)
import pandas as pd
import matplotlib.pyplot as plt
#data input
df_2017 = pd.read_csv('2017_track_analysis.csvのpath', encoding = 'utf-8')
df_2018 = pd.read_csv('2018_track_analysis.csvのpath', encoding = 'utf-8')
df_2019 = pd.read_csv('2019_track_analysis.csvのpath', encoding = 'utf-8')
df_2020 = pd.read_csv('2020_track_analysis.csvのpath', encoding = 'utf-8')
fig = plt.figure()
ax = fig.add_subplot(111)
plt.grid() #グリッド
plot_data = 'danceability' #analysis target
ax.hist([df_2017[plot_data],
df_2018[plot_data],
df_2019[plot_data],
df_2020[plot_data]],
label=['2017', '2018', '2019', '2020'],
bins=10, density=True)
plt.xlabel(plot_data, fontsize=18) #x軸ラベル
plt.ylabel('Count Rate', fontsize=18) #y軸ラベル
plt.title(plot_data + ' Rate', fontsize=18) #x軸ラベル
ax.legend()
plt.show()
結果は以下のようになります。
うまくグラフが取得できていますね。
ここで作成したプログラムを用いて、分析対象を変えてグラフを描写することで冒頭の分析を行いました。
今回は、年ごとの分析を行いましたが、
・同一アーティストのアルバム間の楽曲分析
・国により好まれる楽曲の違いを分析
・グループ曲とソロ曲の傾向の違い分析
などなどアイデア次第でいろんな分析が出来るツールになります。
Let’s enjoy data of music!
To Be Continued :全ての音楽愛好家のためのSpotify API ep 4
PyQさんで勉強中!


コメント